前言
????我们在查询数据库表中,如果没有设置数据重复性校验,可能会插入重复的数据项,那么针对这些重复的数据项可能存在脏数据,当然如果在设计时考虑到并且业务允许重复数据那么这些数据就是有效数据。面对不同的业务逻辑,这些重复数据的处理方式也是不同的,那么本文将简单汇总一下MySQL中重复数据处理的一些方法。
测试数据表
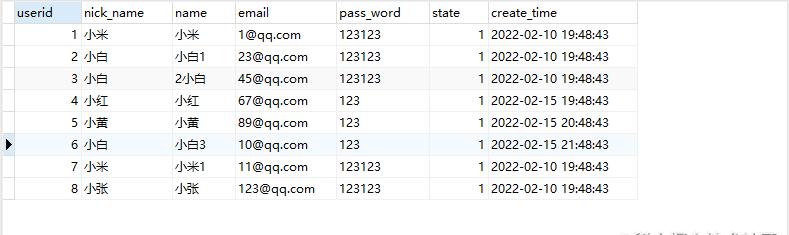
????测试使用数据表s_user
????测试使用数据
INSERT INTO `test`.`s_user` ( `userid`, `nick_name`, `name`, `email`, `pass_word`, `state`, `create_time` )VALUES ( 1, ‘小米’, ‘小米’, ‘1@qq.com’, ‘123123’, 1, ‘2022-02-10 19:48:43’ );INSERT INTO `test`.`s_user` ( `userid`, `nick_name`, `name`, `email`, `pass_word`, `state`, `create_time` )VALUES ( 2, ‘小白’, ‘小白1′, ’23@qq.com’, ‘123123’, 1, ‘2022-02-10 19:48:43’ );INSERT INTO `test`.`s_user` ( `userid`, `nick_name`, `name`, `email`, `pass_word`, `state`, `create_time` )VALUES ( 3, ‘小白’, ‘2小白’, ’45@qq.com’, ‘123123’, 1, ‘2022-02-10 19:48:43’ );INSERT INTO `test`.`s_user` ( `userid`, `nick_name`, `name`, `email`, `pass_word`, `state`, `create_time` )VALUES ( 4, ‘小红’, ‘小红’, ’67@qq.com’, ‘123’, 1, ‘2022-02-15 19:48:43’ );INSERT INTO `test`.`s_user` ( `userid`, `nick_name`, `name`, `email`, `pass_word`, `state`, `create_time` )VALUES ( 5, ‘小黄’, ‘小黄’, ’89@qq.com’, ‘123’, 1, ‘2022-02-15 20:48:43’ );INSERT INTO `test`.`s_user` ( `userid`, `nick_name`, `name`, `email`, `pass_word`, `state`, `create_time` )VALUES ( 6, ‘小白’, ‘小白3′, ’10@qq.com’, ‘123’, 1, ‘2022-02-15 21:48:43’ );INSERT INTO `test`.`s_user` ( `userid`, `nick_name`, `name`, `email`, `pass_word`, `state`, `create_time` )VALUES ( 7, ‘小米’, ‘小米1′, ’11@qq.com’, ‘123123’, 1, ‘2022-02-10 19:48:43’ );INSERT INTO `test`.`s_user` ( `userid`, `nick_name`, `name`, `email`, `pass_word`, `state`, `create_time` )VALUES ( 8, ‘小张’, ‘小张’, ‘123@qq.com’, ‘123123’, 1, ‘2022-02-10 19:48:43’ );
查询重复数据
????示例:测试数据中有很多nick_name昵称重复的数据,那么我们需要查询出nick_name重复的数据。基本执行思路如下:
1、首先定义需要查询的重复的列
2、使用GROUP BY对重复的列进行分组
3、使用HAVING查询出数量大于1的数据
4、可以与查询条件WHERE、Order By排序等一起使用
查询重复数据SQL如下:
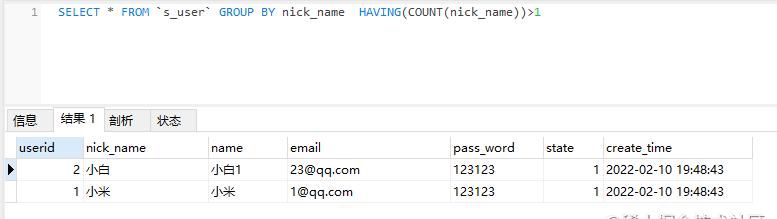
SELECT * FROM `s_user` GROUP BY nick_name HAVING(COUNT(nick_name))>1;
????执行查询重复数据SQL结果如下图:
统计重复数据
????示例:统计数据表s_user中nick_name昵称重复的昵称名称和数量。
????分析如下:
1、需要查询的重复字段为nick_name,
2、需要显示姓名和数量,使用GROUP BY分组查询姓名,查询数量使用COUNT()函数进行数量统计
????统计重复数据SQL如下:
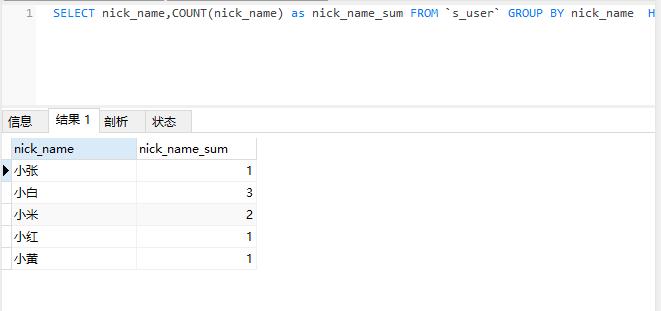
SELECT nick_name,COUNT(nick_name) as nick_name_sum; FROM `s_user` GROUP BY nick_name
执行统计重复数据SQL结果如下图:
过滤重复数据
????在某些业务场景中,不需要出现重复数据,如果数据库中出现了重复数据,需要进行过滤,也就是去除重复数据,我们可以使用GROUP BY或DISTINCT 关键字进行重复数据去除。
????示例:将数据表s_user中nick_name昵称重复的昵称名称去除,只显示一个相同昵称的数据。
????使用GROUP BY进行去除指定字段重复数据SQL如下:
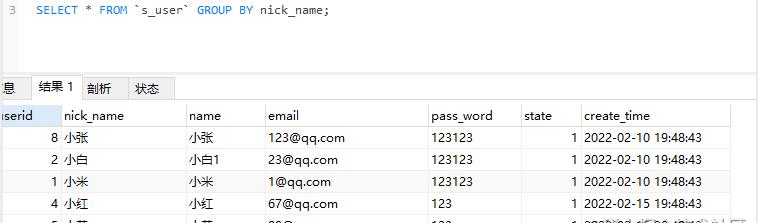
SELECT * FROM `s_user` GROUP BY nick_name;
使用GROUP BY进行去除指定字段重复数据SQL执行结果如下:
 使用DISTINCT 关键字进行去除指定字段重复数据SQL如下:
使用DISTINCT 关键字进行去除指定字段重复数据SQL如下:
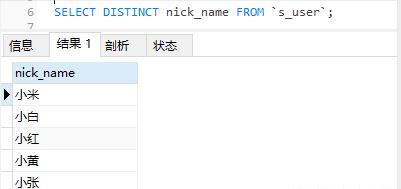
SELECT DISTINCT nick_name FROM `s_user`;
使用DISTINCT 关键字进行去除指定字段重复数据SQL执行结果如下:
删除重复数据
????在某些场景中,数据库表中不能有重复的数据,那么需要将数据清洗一下,删除那些重复的数据再进行其他操作。
????示例:将数据表s_user中nick_name为小米的userid较小的数据删除。
????分析
1、需要查询的字段是nick_name,进行分组,并且查询出userid不是最大的id的。
SELECT*FROM`s_user`WHEREuseridin(SELECTMAX(userid)FROM`s_user`GROUPBYnick_name)ANDnick_name=”小米”
2、将userid不是最大的userid的数据执行删除操作,可以看到要删除userid为1的数据。
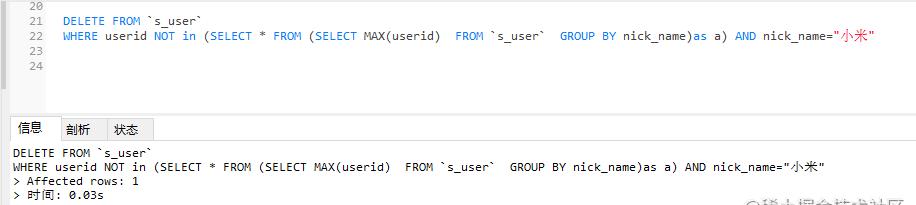
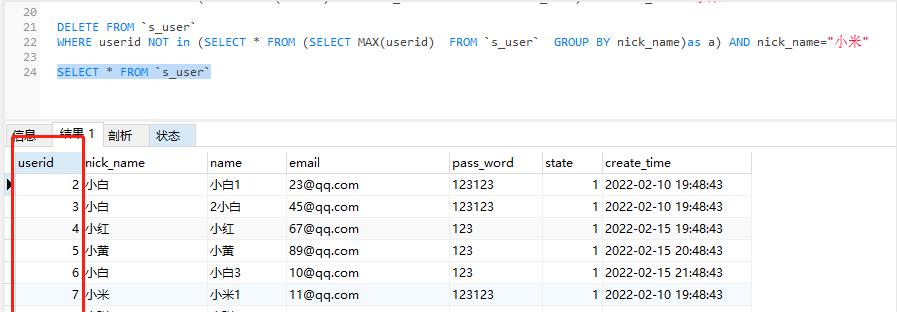
DELETEFROM`s_user`WHEREuseridNOTin(SELECT*FROM(SELECTMAX(userid)FROM`s_user`GROUPBYnick_name)asa)ANDnick_name=”小米”
????执行SQL
????再次执行查询所有数据,可以看到用户昵称为”小米“的userid较小的数据已经删除,只保留了最大的数据。
SELECT * FROM `s_user`
防止重复数据
????在数据库设计初期,如果已经明确数据库表中禁止存在重复数据字段,那么在设计初期可以对重复数据进行校验和限制。
????方式一:使用主键或者唯一索引的方式进行限制,如果插入重复的数据时,SQL将无法插入数据成功并抛出异常。这是从数据库层面防止重复数据。如果不需要抛出异常,则在插入数据库的时候应使用INSERT
IGNORE INTO进行数据保存,如果将要插入的数据不存在,则直接插入数据库,如果插入的数据已经存在则直接跳过这条数据。
????方式二:也可以在业务逻辑中进行重复数据校验,插入之前对可能重复的字段信息进行校验,如果已经存在,提示用户数据已经存在,修改后再保存。
结语
推荐阅读
☆时区的规则发生变化时,JDK如何同步时区
☆只知道JWT,那JWE、JWS、JWK、JWA呢?
☆高并发下如何保证接口的幂等性?
☆电商系统架构, 常见的 9 个大坑 | 库存超卖、重复下单、物流单ABA…
☆阿里开源的10个神级项目,你都用过那个?
☆SQL中常用的约束条件使用
☆【精品】万字讲述:高并发下秒杀商品,你必须知道的9个细节
☆震惊,Spring官方推荐的@Transactional还能导致生产事故?
☆SpringBoot启动时如何对配置文件进行校验?这种方法才叫优雅!(文末福利)
感谢阅读

喜欢这篇文章的话,分享给你朋友哈!