『知者不言,言者不知。塞其兑,闭其门;挫其锐,解其纷;和其光,同其尘,是谓玄同。』
——《道德经》第五十六章

近几年来人工智能技术越来越火热,计算机视觉作为人工智能与计算机科学的一个分支,其技术应用也越来越广泛。由于Python语言有很多计算机视觉处理库,所以Python语言是计算机视觉应用开发重要的语言之一。
本文通过网站验证码识别项目介绍计算机视觉技术和相应库的使用。
 验证码和验证码识别1)验证码
验证码和验证码识别1)验证码
为了防止计算机程序模拟人登录网站进行一些违规操作,如:恶意注册、刷票、论坛灌水等。网站后台生成一个随机编码,当用户登录时不仅要输入正确的用户名和密码,还要输入正确的编码。这个编码就是验证码,缩写为CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart,全自动区分计算机和人类的图灵测试)。
随着人工智能技术的发展验证码越来越复杂。验证码中不仅有简单的字符,还有汉字、数学运算等,而验证码形式也有多种,不仅有图片还有声音等形式。
2)验证码识别
如果说验证码是“道”,那么验证码识别就是“魔”。验证码与验证码识别就是一对矛盾,他们此消彼长的。验证码识别涉及到的技术很多,但核心技术是图像识别和语音识别等知识。
各个网站生成的验证码各有不同,因此验证码识别过程要具体问题具体分析。为了将本章所学内容用于验证码识别,本节介绍的网站验证码识别是相对比较简单的图片验证码,如图26-8所示。

安装Tesseract引擎和相应库
1)安装OCR引擎Tesseract
Tesseract是一个开源的OCR引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。
安装成功需要配置环境变量,将Tesseract的安装目录添加到系统的PATH中,如图2-1所示是在Windows 10下添加PATH。
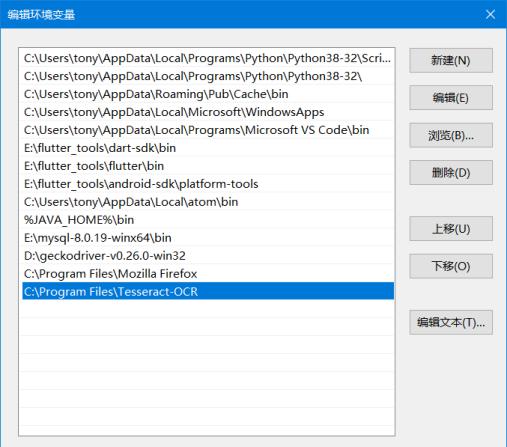
图2-1添加PATH
2)安装pytesseract库
Tesseract既是一个OCR引擎,也是一个OCR工具,读者可以使用tesseract.exe命令工具识别图片中的文字。但是如果要在Python程序代码中调用Tesseract识别图片中的文字,则需要安装pytesseract库。
安装pytesseract库可以使用pip工具,指令如下:
pip install pytesseract -i https://pypi.tuna.tsinghua.edu.cn/simple其他平台安装过程也是类似的,这里不再赘述。
安装pytesseract库成功后,还需要配置环境。在Python安装路径下Lib\site-packages\pytesseract目录中找到pytesseract.py文件,如图2-2所示。
图2-2添加PATH
修改pytesseract.py文件,主要代码如下:
…try: from PIL import Imageexcept ImportError: import Image# tesseract_cmd = ‘tesseract’ ①tesseract_cmd = r’C:\Program Files\Tesseract-OCR\tesseract.exe’ ② numpy_installed = find_loader(‘numpy’) is not Noneif numpy_installed: from numpy import ndarray…
首先找到代码第①行tesseract_cmd = ‘tesseract’修改为代码第②行所示内容。tesseract_cmd是指向Tesseract引擎中的tesseract.exe文件。
3)安装pillow库
安装pillow库可以使用pip工具,指令如下:
pip install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple其他平台安装过程也是类似的,这里不再赘述。

验证码识别代码实现
验证码识别过程分为两个阶段:图像处理和图像识别。
1)图像处理
图像处理包括灰度化、二值化、降噪、切割和归一化等。在图像识别、验证等处理时,需要对图像进行灰度化后再进行二值化处理。图像灰度化是将3个颜色通道的原始图像(如图3-1(a))变为1个通道的灰度图像(如图3-1(b)所示),灰度图像虽然只有一个颜色通道,但灰度取值是0~255连续的整数。图像二值化就是将图像上像素点的灰度值重新设置为0或255两个极端值,二值化后的图像只有黑和白的视觉效果,如图3-1(c)所示。降噪是减少图像中的干扰因素,包括:随机颜色字符、随机颜色背景、干扰线、干扰点等,事实上二值化也是为了降噪,二值化可以取出颜色差别比较大的干扰线和干扰点。切割是从图像中切割出单个的字符图像,这是为了便于识别处理。归一化是将切割后的图像调整为相同大小的图像,这是也为了便于识别处理。

(a)彩色图像 (原图)

(b) 灰度图像 (c)二值化图像
图3-1 灰度图像和二值化图像
2)图像识别
图像识别包括特征提取、训练和识别。这个过程一般可通过机器学习或深度学习算法进行,但本例中Tesseract引擎可以完成识别过程。实现代码如下:
# coding=utf-8# 代码文件:code/chapter26/26.4项目实战/ch26.4.6.pyimport cv2import pytesseract as tessfrom PIL import Imageimport matplotlib.pyplot as plt# 设置中文字体plt.rcParams[‘font.family’] = [‘SimHei’]# 1.读取图片src_image = cv2.imread(“./captcha_img/test2.png”) ①# 2.转为灰度化图像gray_image = cv2.cvtColor(src_image, cv2.COLOR_BGR2GRAY) ②# 3.转为二值化图像th_image = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 21, 1) ③ pil_image = Image.fromarray(th_image) ④# 转文本显示text = tess.image_to_string(pil_image) ⑤print(text.replace(‘ ‘, ”))titles = [‘原始图像’, ‘灰度图像’, ‘二值化图像’] ⑥images = [src_image, gray_image, th_image]for i in range(3): plt.subplot(3, 1, i 1) plt.imshow(images[i], ‘gray’) ⑦ plt.title(titles[i])plt.tight_layout() # 调整布局plt.show() # 显示图像 ⑧
上述代码第①行~第③行是图像的处理过程,其中代码第②行是图像灰度化处理。代码第③行是图像二值化处理过程,其中采用自适应阈值进行二值化处理。
代码第④行、第⑤行是图像的识别过程,其中代码第④行从NumPy数值对象th_image创建PIL中的Image图像对象。代码第⑤行使用pytesseract 中image_to_string()函数识别图像中的字符。
为了看到比较处理过程中不同阶段的图像,代码第⑥行~第⑧行将多个图像显示到一个窗口中。
上述示例程序运行后在控制台中输出识别文字是:
qYwpN并在窗口中显示如图3-2所示图像。

图3-2 绘制图像

赠书活动
书名:Python从小白到大牛(第2版)
书号:9787302562474
定价:99.00
高校教师(普通高校/职业院校教师)

其他读者(科研/工程人员/大学生)
按下述步骤抽奖获样书