人本计算机视觉在过去几年中取得了巨大的进步,这在很大程度上得益于大量标注好的人像数据。然而,由于隐私、法律、安全和道德问题的限制,我们获取的人像数据仍然有限。同时,现存数据集在采集和标注时还存在一定的偏差,对受训模型产生不良影响。此外,这些数据并没有对内容多样性、人体运动与姿势,及域脱离(domain-agnosticism)作适当分析。
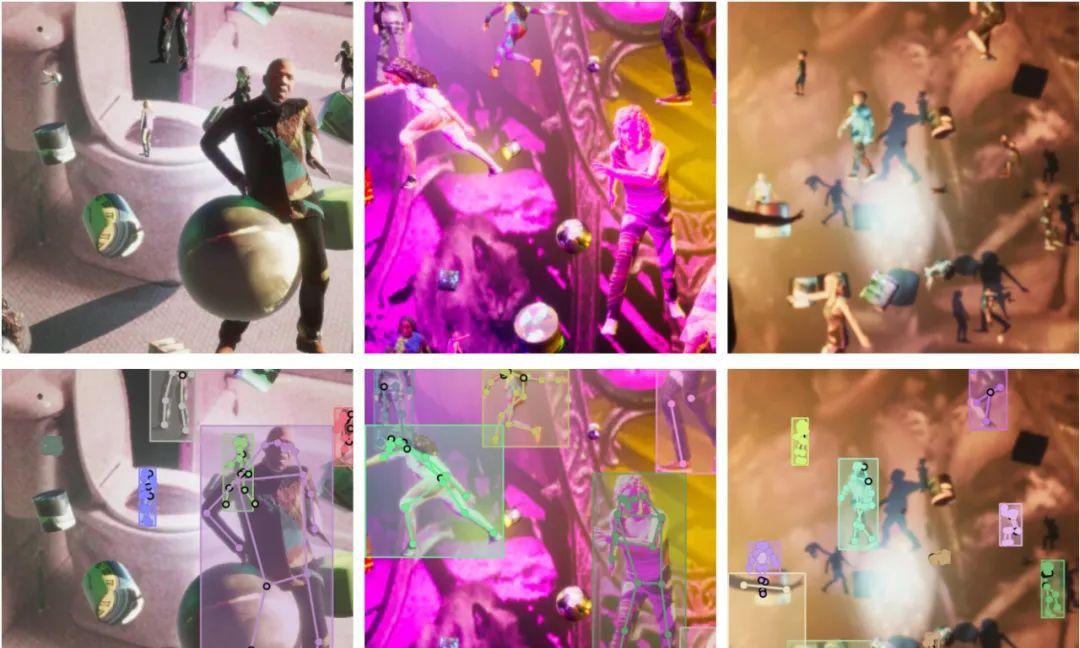 PeopleSansPeople样本的图片标签上列:三张根据样本生成的合成图像下列:带有边界框与COCO姿势标签的图像
PeopleSansPeople样本的图片标签上列:三张根据样本生成的合成图像下列:带有边界框与COCO姿势标签的图像
为了应对以上挑战,Unity 荣幸地推出 PeopleSansPeople,一款以人为主题、高度参数化的数据生成器,它带有现成的 3D 人类模型、参数化的光照系统、摄像机系统、环境生成器,以及完全可控且可扩展的域随机生成器。PeopleSansPeople 借助 JSON 文件生成的 RGB 图像带有精细到亚像素 2D/3D 边界框、符合 COCO 标准的人体关节点以及环境/实例分割遮罩。
PeopleSansPeople:
https://github.com/Unity-Technologies/PeopleSansPeople
我们在最近的一次基准测试中就使用了 PeopleSansPeople 和 Detectron2Keypoint R-CNN 变体。测试发现,如果用合成数据预先训练神经网络,并微调真实的识别目标数据(比如用 COCO-persontrain 部分子图集形成小样本),可让 Keypoint AP 达到 60.37±0.48(以 COCO test-dev2017 为基础),优于仅使用同一套真实数据训练的(Keypoint AP 得分 55.80)和使用 ImageNet 预训练的(Keypoint AP 为 57.50)模型。
相关详情请见这篇论文:
https://arxiv.org/abs/2112.09290
在人本计算机视觉领域,PeopleSansPeople 将促成并加快相关合成数据实用性的研究。在打造 PeopleSansPeople 之际,我们就考虑到研究人员对与人相关的随机性合成数据的需求,并因此扩展了模拟器在 AR/VR、自动驾驶、人体姿势估计、动作识别和跟踪等现有或全新领域的模拟能力。PeopleSansPeople 数据最有意思的研究方向是生成合成数据,它们将模拟到真实(sim2real)的迁移学习联系起来、并消除合成数据和真实数据之间的差距。
PeopleSansPeople发行版
我们发布了两个版本的 PeopleSansPeople:
首先是在 macOS 和 Linux 上的可执行文件,可用于生成带有 JSON 变量配置文件的大规模(一百万以上)数据集。它包括:
 28 种不同年龄和种族的 3D 人体模型,多种服装:由albedo(28张)、遮罩(28张)和法线贴图(28张)组成的独特的衣物纹理(21952张);
28 种不同年龄和种族的 3D 人体模型,多种服装:由albedo(28张)、遮罩(28张)和法线贴图(28张)组成的独特的衣物纹理(21952张);
39 种动画片段,完全随机化的模型摆放、大小和转向,多样化的人体模型排列;
完全参数化的光照(位置、颜色、角度和强度)和摄像机(位置、转向、视场、焦距)设置;
一组可用作干扰物或遮挡物、带有多种纹理变体的基本物体;
一组取自 COCO、未标记的、用作背景或纹理的未处理图像(1600张)。
第二,我们发布了一个 Unity 模板项目,降低了准入门槛,帮助社区自行定制数据生成器。每位 Unity 用户都可将自己的 3D 资源导入模板,通过调整现成的域随机程序或编写新的随机程序来扩大其应用范围。
除了包含前一个可执行程序的全部功能外,该模板还将带有:
4 种衣着各异的 3D 人体模型;
8 段动画片段,模型摆放、大小和转向完全随机,以生成各种人像;
一组取自 Unity Perception 包、用作背景和纹理的 529 张百货商品图片。
Unity Perception包:
https://github.com/Unity-Technologies/com.unity.perception
PeopleSansPeople的域随机化
PeopleSansPeople 是一个参数化的数据生成器,它通过一个简单的 JSON 配置文件将几个生成参数外露出来,并且所有配置还能直接在 Unity 中更改。该数据生成器的主题是人本任务,因此域随机化和环境都围绕着完全参数化的人体模型而设计。在这些参数的帮助下,我们就能在人体模型上实现身体或外观上的变化。
服装借助了 Shader Graph 随机程序来改变纹理,并生成图 3 和图 4 中的多样化人物。我们还用到了动画随机程序让模型在多种人体动作和姿势中随机播放,如图 5 所示。


图3:PeopleSansPeople三维人体模型。
第一张:28个扫描而成、应用了默认姿势与服装纹理的3D人体模型。
第二张:用Unity Shader Graph随机化服装纹理的例子。

图4:Shader Graph随机化程序可改变服装纹理的albedo、mask和normal贴图,产生独特的迷彩样纹理,随机变化的颜色能让角色更显多样。尽管衣服的纹理非常多样,我们仍期待模型能不受其颜色和纹理的变化影响而出错。

图5:用动画随机器让人物姿势更多样。
为了让模型能够应用到现实中,我们通过域随机化来改变模拟环境的各个方面,让合成数据能产生更多的变化。我们的随机程序依靠预先定制的 Unity 场景组件运作。在模拟期间,程序会使用正态分布、均匀分布和二项分布法来取范围内的参数随机值并应用。简单来说,就是随机化 3D 物体的摆放和姿势、场景内的纹理和颜色、光照的配置和颜色、摄像机参数和一些后期处理效果等。而光照、色调、摄像机机旋转/视场/焦距等随机化则参考了标准的数据增强(data augmentation)流程。模型在训练期间无须扩充数据,训练过程也能更快。
数据集统计分析
我们用域随机化生成了带有 500,000 张图片与标签的合成数据集,其中的 490,000 张图像用于训练,剩余 10,000 张用于检验。如果将合成数据集的统计数据与 COCO 数据集进行比较,可以看出前者比后者的实例要多出一个数量级,而带注释的实例也要多出一个数量级,如表1所示。
 表1:COCO和PeeopleSansPeople之间的大致比较。合成数据集有着更多带注释和关键点的实例。
表1:COCO和PeeopleSansPeople之间的大致比较。合成数据集有着更多带注释和关键点的实例。
图 6 展示了三组数据集的边界框占有率热图。由于 COCO 数据集带有大量肖像和风景照,长方形边界框会随着图像的高宽而变化。大多数边界框都聚集在图片中心,鲜有向边缘扩张的情况。在 PeopleSansPeople 合成数据上,边界框能更好地覆盖整张图片,并迫使模型处理整块感受野(Receptive Field)。
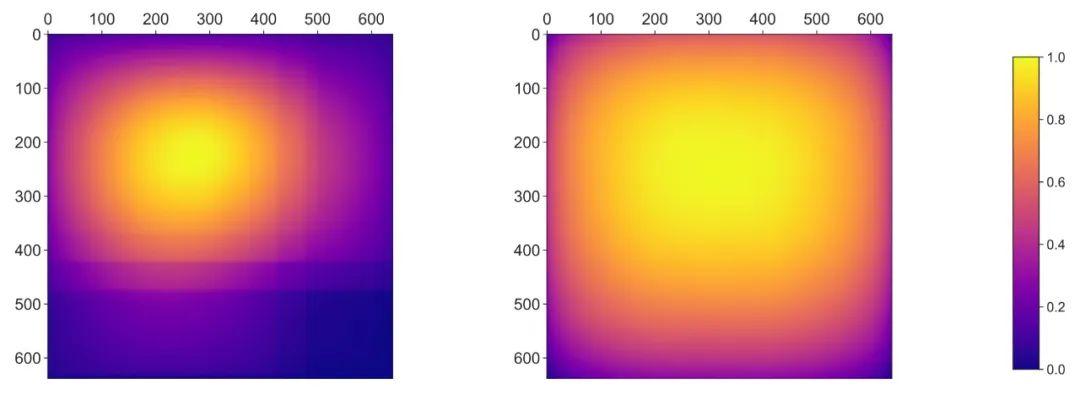 图6:边界框覆盖率热图。热图通过在图片上覆盖盒型图案得出。我们将合成数据集与COCO作了一个比较。
图6:边界框覆盖率热图。热图通过在图片上覆盖盒型图案得出。我们将合成数据集与COCO作了一个比较。
图 7 则比较了边界框和关键点的统计数据。从数字里可看到,合成数据集的每一张图片上都有更多的边界框,而 COCO 的图片大多只有 1 到 2 个边界框(图7a)。另外,合成数据集的边界框大小更均匀,而 COCO 的边界框大多很小(图7b)。合成数据集的大多数边界框都有完整的关键点注释,但 COCO 的大多数边界框却没有(图7c)。最后在有关键点注释的边界框上,合成数据集有为个别键点添加注释的可能性加倍(图7d)。
图7:边界框与关键点统计。a) 每张图像的边界框数。b) 相对于图像的边界框大小。
最后,为了量化人体模型姿势的多样性,我们在角色的肢体加上了五个代表性的关键点,据此生成图 8 热图来展示最大的肢体移动距离。可以观察到:
PeopleSansPeople 的姿势分布包含了 COCO 中的姿势分布;
合成数据的姿势分布要比 COCO 更广;
COCO 的多数人像多为正面朝向镜头,导致了关键点在部分位置过于密集,有种“刻意”感,这在合成数据中是没有的。
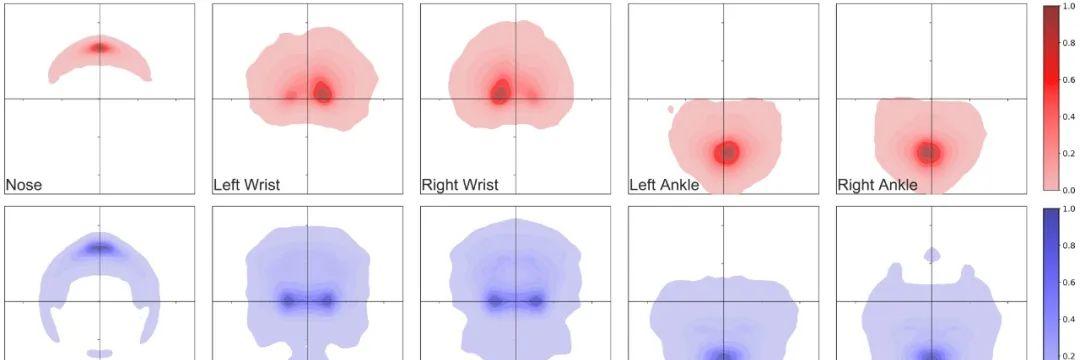
图8:五个关键点的位置热图。第一排:COCO。第二排:PeopleSansPeople。
检测PeopleSansPeople开箱即用的效果
为了检测转移学习训练结果的基准表现,我们多次修改了合成和真实数据集的大小和组合,用于训练人体边界框(bbox)和关键点识别。我们以平均精度(AP)为指标来检验 COCO人 物验证(personval2017)和测试集(test-dev2017)上的模型性能。
模型使用了随机化的权重和 ImageNet 预训练的权重来进行训练。人本计算机视觉在过去几年中取得了巨大的进步,这在很大程度上得益于大量标注好的人像数据。实际上,数据集的生成采用了最为直接的参数范围,还通过均匀采集参数来强制生成数据。因此数据生成的结果非常原始。
表 2、表3 和表 4 展示了我们的成果。可以看到,使用合成数据预训练、经现实数据微调的模型要强于仅使用真实数据训练的模型,以及使用 ImageNet 预训练、经真实数据微调的模型。这种优势在真实数据有限的小样本转移学习中更为明显。而在数据丰富的情况下,使用合成数据的预训练仍具有优势。

表2:合成预训练、从零训练和ImageNet预训练的收益比较。COCO人类验证集的边界框检测结果。

表3:合成预训练、从零训练和ImageNet预训练的收益比较。COCO人类验证集的关键点检测结果。

表4:合成预训练、从零训练和ImageNet预训练的收益比较。COCO测试集的关键点检测结果。
注意,这些数据的主要作用是标出 PeopleSansPeople 数据的基准。高度参数化的 PeopleSansPeople 允许用户轻松地自定义随机化程序。我们希望 PeopleSansPeople 能让模型训练流程的超参数调整和数据生成研究成为可能,借此提高数据在零样本、少样本和完全监督学习中的作用。并且,带有丰富且精确标注的合成数据可以与少量甚至无标注的真实数据结合使用,实现弱监督训练。
结论
本文介绍了用 Unity 合成数据展开的人本计算机视觉研究。我们制作的这个高度参数化的合成数据生成器被亲切地命名为 PeopleSansPeople,它将在人本计算机视觉领域促成并加快相关合成数据实用性的研究。PeopleSansPeople 提供了模拟参数和域随机化的精细控制,为模型训练流程中的元学习和数据生成开辟了道路。
为了验证和衡量 PeopleSansPeople 的参数化,我们还进行了一系列的基准测试。测试表明,即使是最原始的随机化数据也能得到改善。希望 PeopleSansPeople 和这些基准测试能够促成对模拟与现实的广泛研究,包括但不限于模型训练策略、数据超参数搜索和替代数据生成策略。
更多详情请查看以人为中心的数据生成器的源代码和论文。
源代码:
https://github.com/Unity-Technologies/PeopleSansPeople
论文:
https://arxiv.org/abs/2112.09290





第一时间了解Unity引擎动向,学习最新开发技巧