以下内容包括RedHat和CentOS运维工作中常用的几大技能,并总结了系统运维中网络方面的规划、操作及故障处理等知识。来自社区交流,多位会员分享,董志卫整理。
一、Linux 系统日常运维九大技能
1、安装部署
方式:U盘,光盘和网络安装
其中网络安装已经成为了目前批量部署的首选方式:主要工具有Cobbler和PXE kickstart
可以参考如下链接内容:
http://www.cnblogs.com/mchina/p/centos-pxe-kickstart-auto-install-os.html
2、初始化配置
禁用服务

禁用SeLinux

配置YUM源配置
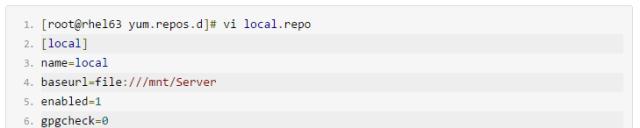
可以配置为光盘,内部YUM源或EPEL等
常用软件安装

安装xwindows
 配置ntp
配置ntp

Crontab 添加如上记录,指定内部ntp服务器
SSH 登录设置
修改ssh 禁用DNS 选项:

添加允许指定用户登录:

上传扫描工具

网络上有该脚本,下载自行使用
修改历史记录格式
 3、安全加固本次安全加固内容主要参考的是Redhat和Centos系列版本系统:
3、安全加固本次安全加固内容主要参考的是Redhat和Centos系列版本系统:
参考链接http://www.centoscn.com/CentosSecurity/CentosSafe/2015/0315/4881.html
注释掉系统不需要的用户和用户组
注意:不建议直接删除,当你需要某个用户时,自己重新添加会很麻烦。

关闭系统不需要的服务

给下面的文件加上不可更改属性,从而防止非授权用户获得权限
 限制不同文件的权限
限制不同文件的权限
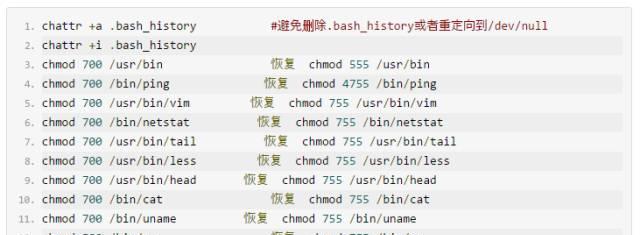 禁止使用Ctrl Alt Del快捷键重启服务器
禁止使用Ctrl Alt Del快捷键重启服务器

使用yum update更新系统时不升级内核,只更新软件包
注意:由于系统与硬件的兼容性问题,有可能升级内核后导致服务器不能正常启动,这是非常可怕的,没有特别的需要,建议不要随意升级内核。
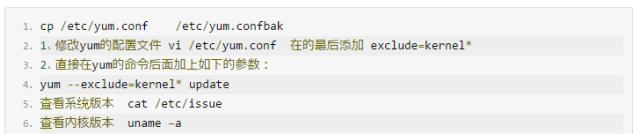
关闭Centos自动更新
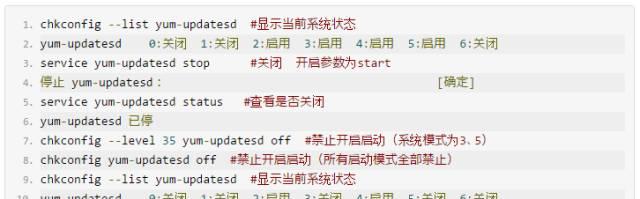 关闭多余的虚拟控制台我们知道从控制台切换到 X 窗口,一般采用 Alt-F7 ,为什么呢?因为系统默认定义了 6 个虚拟控制台,
关闭多余的虚拟控制台我们知道从控制台切换到 X 窗口,一般采用 Alt-F7 ,为什么呢?因为系统默认定义了 6 个虚拟控制台,
所以 X 就成了第7个。实际上,很多人一般不会需要这么多虚拟控制台的,修改/etc/inittab ,注释掉那些你不需要的。
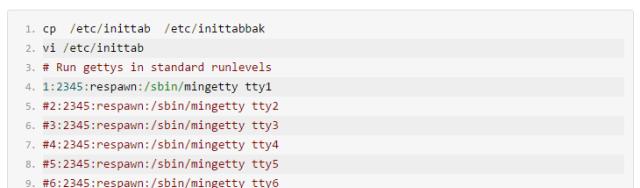
修改history命令记录
 隐藏服务器系统信息
隐藏服务器系统信息
在缺省情况下,当你登陆到linux系统,它会告诉你该linux发行版的名称、版本、内核版本、服务器的名称。
为了不让这些默认的信息泄露出来,我们要进行下面的操作,让它只显示一个”login:”提示符。
删除/etc/issue和/etc/issue.net这两个文件,或者把这2个文件改名,效果是一样的。

优化Linux内核参数
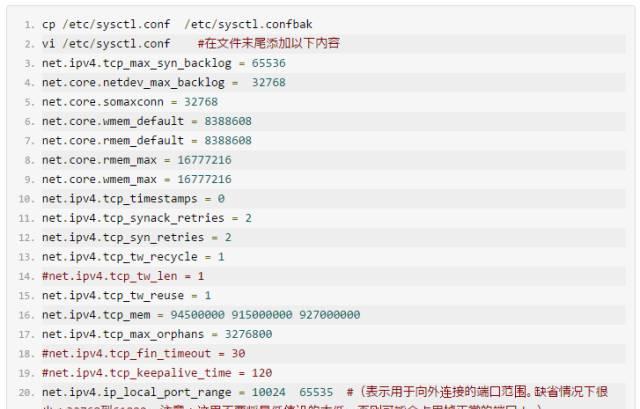 系统优化
系统优化
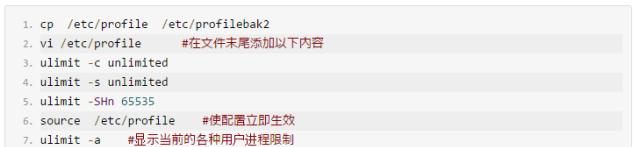 服务器禁止ping
服务器禁止ping
 检查口令策略设置是否符合复杂度要求
检查口令策略设置是否符合复杂度要求
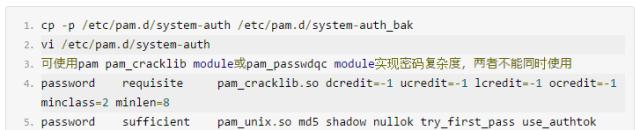 检查登录提示-是否设置登录成功后警告Banner
检查登录提示-是否设置登录成功后警告Banner
修改文件/etc/motd的内容,如没有该文件,则创建它。

检查是否设置登录超时
执行备份:

修改/etc/csh.cshrc文件,添加如下行:

改变这项设置后,重新登录才能有效
5、多路径设置
随着X86 环境的普及化,Linux 的市场占有率也越来越高,为了方便后续的设备管理我们和Linux 自带多路径软件的成熟化,我们在日常的设备多路径软件选择方面经常会首先考虑使用DM 软件,本次多路径设置主要是结合REDHAT和CENTOS自带软件DM— Multipath
6、系统异常性能指标获取CPU占用最高的10个进程

内存占用最高的10个进程
 虚拟内存使用最多的前10个进程
虚拟内存使用最多的前10个进程

查看系统负载

统计当前连接数

当前连接数最多的10个进程

6、LVM日常使用
LVM在日常运维工作当中占据着很大的比重,在此我列举LVM常见的日常操作及步骤。
1. 添加一个磁盘到OS,格式化文件系统使用,参考如下:
扫描磁盘
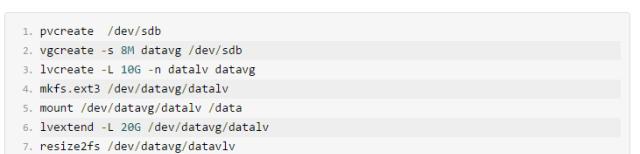
这个其中每个步骤就不在做详细解释,有兴趣的可以独自搜索
2.文件系统的扩容和缩小(根文件系统缩小要相当的慎重)
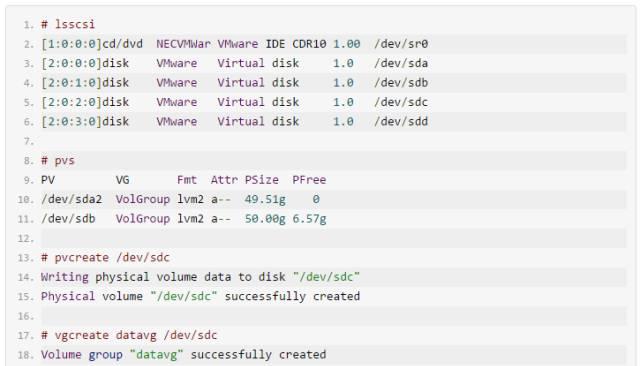

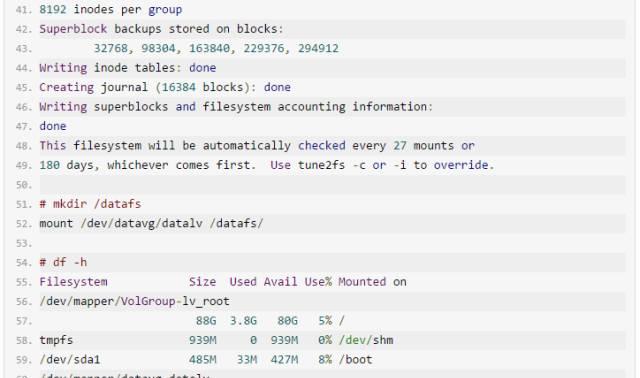
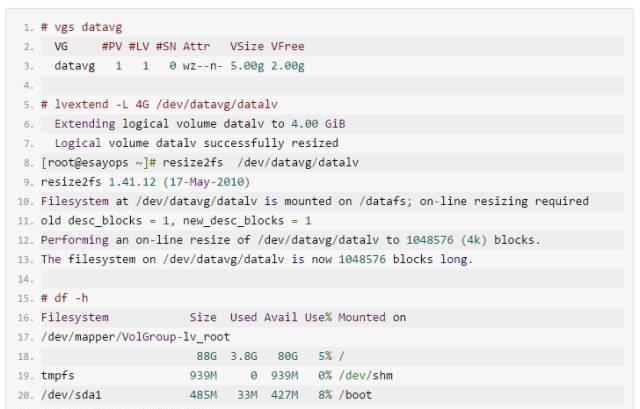
在线扩容文件系统:
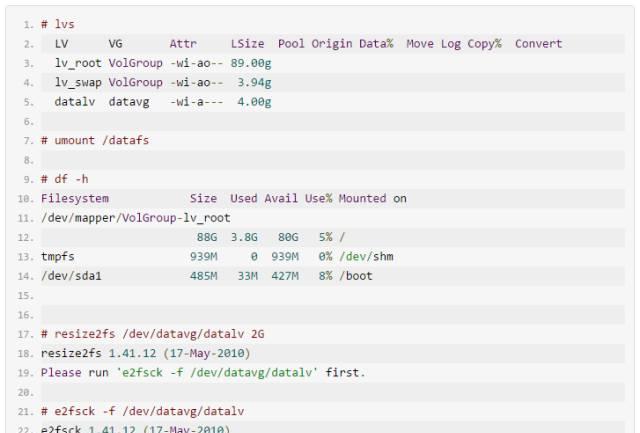
缩小文件系统:
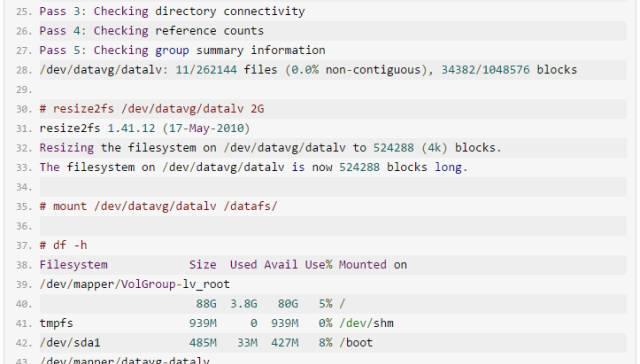
3. 在线删除一个共享磁盘LUN
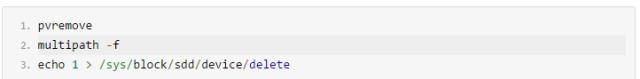
例如:
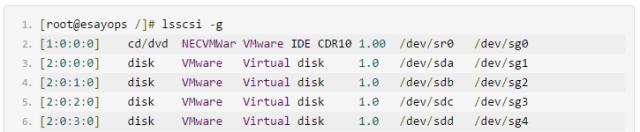
删除一个不用的lun
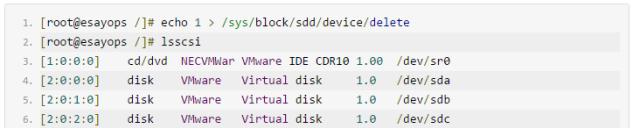
删除环节:

7、Linux 运维命令掌握
Linux 下面日常运维使用的命令有太多了,可以根据个人的情况进行适当的记忆。
系统负载:top ,nmon,dstat 等
网络:ss,netstat,route,diag,ping,ip,lsof 等
io:dd,iostat,fio,nmon,dstat,pvs,lvs,vgs 等
内存:free,dstat等
进程:ps,lsof 等
配置:lscpu,lspci,dmidecode,lsscsi,udev 等
设备识别:echo ‘—‘ ,rescan-scsi-bus.sh 等
诊断:strace,ltrace等
比如还有find如何结合xargs,tree的使用,lsblk 等等,还有很多很多,需要长期的积累,当然主要使用还是配置查看,LVM设置,网络
还有很多成熟的开源和商业产品进行管理,在此不一一列举,感觉可自行百度和google。
目前主流的python,ruby这些语言工具可以根据自身情况选择一个掌握。
8、诊断工具
在日常的运维过程当中,不免要进行所谓的性能或者故障方面问题的诊断,工具和手段包罗万象,在此列举一些日常使用的工具用于参考。
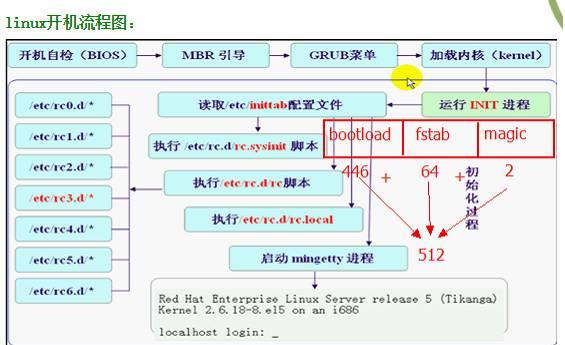
这里附上一幅Linux 开机流程图,这样很多人就可以更加清楚的了解了Linux在启动的整个流程,便于此类问题的解决。
9、网络必杀技
Netcat,SSH 几种隧道转发模式 ,lsof,dstat ,ethtool,iptraf,iperf,diag,route 和多个网卡路由及双网卡绑定技术值得了解,这些都是os层面运维网络方面经常会使用到的几个方面
在日常较为常用的操作就是进行双网卡的绑定,下面分享一个绑定的具体流程:
1、cp /etc/sysconfig/network/ifcfg-eth0 /etc/sysconfig/network/ifcfg-eth0.bak
cp /etc/sysconfig/network/ifcfg-eth0 /etc/sysconfig/network/ifcfg-bond0
2、vi /etc/sysconfig/network/ifcfg-eth0,注释所有(除以下两行内容),并将值修改如下:
BOOTPROTO=’none’
STARTMODE=’off’
3、cp /etc/sysconfig/network/ifcfg-eth0 /etc/sysconfig/network/ifcfg-eth1
4、vi /etc/sysconfig/network/ifcfg-bond0,增加或更新如下内容,其他内容可注释:
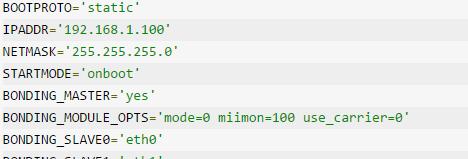
说明:以上配置mode=0为负载均衡模式,如果需要配置成主备模式,BONDING_MODULE_OPTS配置如下:
BONDING_MODULE_OPTS=’mode=1 miimon=100 use_carrier=0 primary=eth0′
5、rcnetwork restart,重启网络服务生效,并进行测试。
6、cat /proc/net/bonding/bond0 可以查看bonding的状态。
二、Linux 系统运维的网络知识总结
1、系统运维中网络方面的规划与思考
在很多公司,岗位职责都是很明确的,专职转岗,每人或者每组负责一块业务。系统运维岗基本上在IT架构上相对偏后一些,该岗位和网络管理岗基本上是平行的。因为今天咱们说的是系统运维方面网络方面的事情,或多或少都会和网络岗打交道,那么谈一点网络岗的内容就显得很有必要。
系统运维建立在网络的基础之上,如果没有一个相对合理的网络架构,恐怕系统运维做起来也不是那么的顺手。一个公司基本上都会把网络和服务器独立开来,划分不同的区域摆放设备,很多时候都是物理隔离。服务器接入交换机大多是经过配线架连接起来和有的服务器机柜头柜安装网络交换机,是相对比较常见的两种方式。

走线从侧面可以反映一个企业对IT的重视程度和投入,很多企业是做不到如图这么漂亮的效果的。这一切一切还要立足于预算,现在基本上没有预算啥事也干不了。
大多数IT机房当初建立的时候,从设备混乱摆放到区域明确划分存放,又从区域功能明确到后来的后来的功能区域模糊,都反映了一个问题:计划赶不上变化。十年前还相当前卫的规划,到现在已经跟不上时代,这并不是谁的错,还是要求我们去适应去改变,业务引领变革,基础架构也需要做相应调整,所谓唯一不变的就是变。
我心中企业目前现阶段相对比较理想的架构这样的,如图所示:
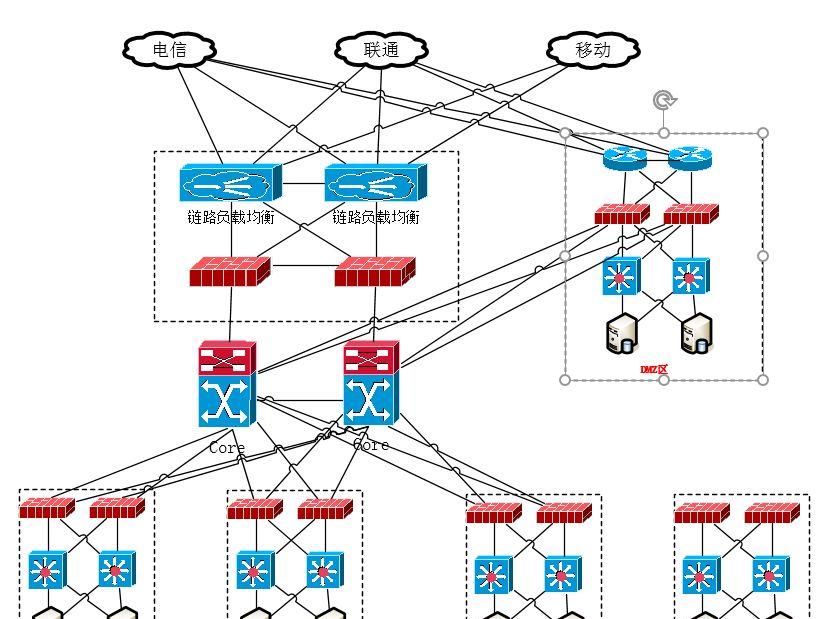
这样后端业务系统在连接网络层面稳定性就有了保障,在主机系统层面,尽量避免单独问题,消除性能瓶颈,异常能够自动告警自动修复得相对比较完美,当然这一切还要立足于预算。
2、系统运维中网络方面操作梳理
在系统运维中,经常涉及的网络方面的操作,一般由以下几个方面组成。
1.设备上线,物理连线设置
很多运维人员要从事从刚开始立项到项目上线再到后期运维的一条龙服务,每个环节都要自己亲自动手,这是好事也是坏事,好的是自己的环境一般会非常的熟悉,不好的是事必躬亲,不出活,业绩不明显。插个线都要自己来,你恐怕也没太多精力干其他的,这就是个矛盾体,自己把握就好。
2.网络逻辑配置调整
这一块内容就涉及到了具体的操作,你可以手工一步一步操作,也可以借助高大上的工具批量完成,这个要看企业的IT建设的能力。一个掩码一个点错误都会导致网络连接异常。如果自己有开发能力也可以使用脚本或语言写成成型的东西,平时多多积累,使用的时候就会方便很多。
具体内容涉及:
1) 配置ip,别名,设置个端口监听,绑定个网卡,设置个路由
2) 划分个vlan,配置个trunk
3) 测试个端口,配置个监控
具体的操作过程在此不做过多的介绍,比如做个网卡绑定啊,测试个端口啊,这些操作网上有大批的文档可以查阅,本节内容就是描述在日常的Linux系统运维方面所涉及网络方面的操作,有一个整体的印象。
3.性能分析与优化
该部分内容相对不太容易操作,不是随随便都可以依葫芦画瓢就能完成,性能稳定分析和定位相对困难一些,很多场景都需要结合多个方面进行统一分析。这个需要一些工作经验的结论和沉淀,选择合适的工具,多方面配合往往会有比较好的效果。
工欲善其事,必先利其器:
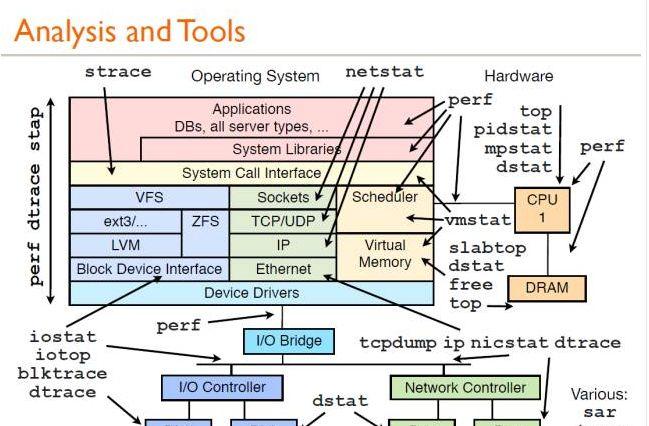
熟练掌握该图上面的各种工具,基本上可以解决性能分析99%的工作,那剩下的1%的不是bug就是天灾。这里其实在说笑了,但这也说明一个好的工具有多么的重要。剩余就是要仔细认真,再好的工具,不会用也不行,态度是第一位的。
3、系统运维过程中需要掌握的利器
在上文中分享了一个图,该图涵盖的面比较广,本节内容主要针对网络方面进行一些梳理,分享一下在工作当中经常使用的利器。
首先我们来分享一张目前Linux 系统性能查看调优工具图:
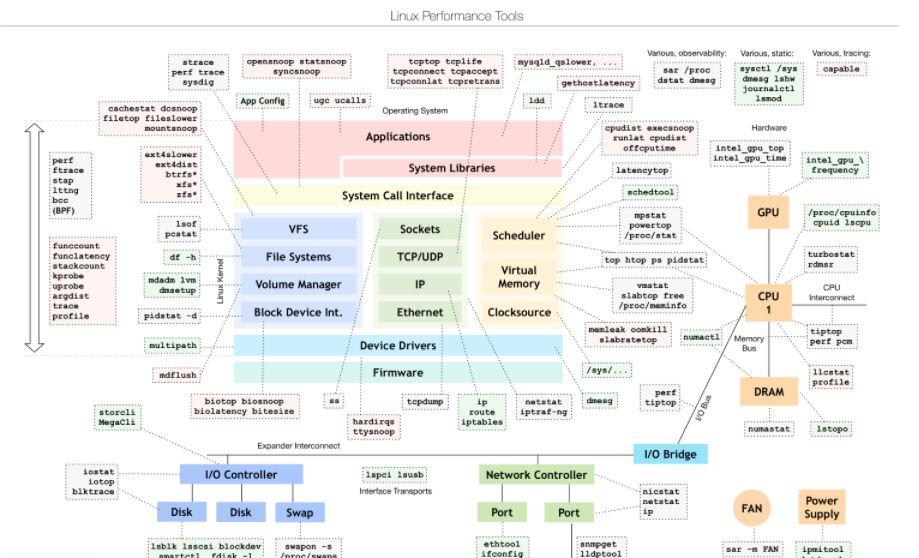
这张图片基本上涵盖了Linux系统各个方面的性能工具,可以说相当的全面,下面我们看一下有关网络方面我们常用的命令或工具有哪些,这样有助于大家方便查看和使用。

以上工具基本上在日常工作当中经常会使用到,每个工具都有其侧重点,这里列举的只是大量工具中的一小部分,因为每个人使用习惯不一样,各有侧重,选择适合自己就好,以上工具仅供参考。
本文内容意在梳理分享,不在具体的工具使用方面做更加深入的讲解,因为每一个工具如果详细讲起来都会涉及大量篇幅,也不可能面面俱到,有兴趣的可以在社区或搜索引擎搜索之。
推荐小工具:
Dig,ethtool,iperf,iftop,dstat,mtr
比如在你想知道两个主机之间的带宽是否能够到达相应的带宽,请使用iperf。想动态的查看目的地是否可到以及延迟等信息,请使用mtr。
4、故障的诊断与分析
故障诊断处理方面不是一两句话就可以说清楚的,很大程度上在于平时经验的积累,很多故障都是相互关联的,如何顺藤摸瓜,找到问题的最终原因,有一些方法可以借鉴。这里不具体描述解决那个问题用了什么方法,只是聊聊解决问题有哪些经验和技巧。
分享一点小小的经验:
a)平时要多问几个为什么
c)多方面相互参考,同事之间相互配合
d)可以多做几个假设,直到推翻自己的想法
e)自己的工具箱要有几个使用顺手的TOOLS,包括自己开发的
以上只是一些解决问题的方法,具体问题还要具体分析。
下面我们结合一个真实的案例来描述一下:在出现网络故障时,。我们如何想办法快速的排除问题。
场景描述:
某日下午,公司里内部的业务系统突然出现反应比较慢的问题,多个业务管理员过来描述问题现象。近期一段时间内曾出现过类似的问题,该类问题的原因是由于业务区的防火墙老旧,处理能力不足,导致CPU在短时间内使用率激增,超过了境界阈值很多,导致此类现象的发生。
解决思路:
1)初步定位
又是类似问题的出现,肯定不是个别业务系统的问题,一看就是有共性的,问题应该是出现在网络设备上才对,这样才会造成大面积的问题,可是该防火墙一周前已经升级换代了,不应该有此类问题了。查看业务区域拓扑,因为拓扑已经在心中,直接搞起。
2) 逐步排查
首先登录新的防火墙,查看CPU使用率,一切正常,看来问题不在此。
然后登录业务系统去交换机查看负载,一看果然是高,高达99%,我勒个去,配合网络管理员查看问题原因,查看各种性能信息,初步没有太合理的线索,不能精准定位问题。收集各种信息准备发给厂商支持。
3) 协助排查
多方回忆近期有无做过其他操作。
网络方面:一周前升级换代该区域防护墙
主机方面:昨天接入6太新设备,并做端口绑定bond
4)再次排查
由于该区域Windows主机设备均已经安装杀毒软件,病毒的可能性不大,Linux 病毒可能性就更小了,先初步忽略。由于昨天上线6个主机设备,着重观察网络设备所连接端口,
通过交换机和监控性能视图分析该端口今天出现流量过大的问题,端口饱和。由于影响业务面比较广,需要快速定位问题或者暂时消除影响。初步意见,交换机上线shutdown 这6台机器所连端口。持续观察了一段时间,交换机CPU 负载下来了,其他业务逐渐恢复。考虑到已经下班,暂时观察一下,明天看情况再做调整。并结合一下厂商意见。
5)第二日上班后,6台机器业务恢复,交换机CPU负载又上来了,但是其他业务没有影响,什么情况?再次进行梳理,找问题线索。
6) 进一步排查
7) 系统进一步排查
我做了很多次bond了,就算这次换了一个高版本操作系统应该也没有问题啊,果断检查之,查看绑定模式,一看模式为0,当时一惊,不应该啊。进一步查看确实是模式配置错误了,当初我想设定的是模式6,后来不知道怎么写成0了,以为其他机器都是拷贝过去的,所以都是模式0了,立马改之。重启网卡,一切看似正常,重新插入网线观察交换机CPU 负载很稳定。这次CPU高应该是这个引起的无疑了,这个锅扣到我脑袋上了。
8)下午14:00,问题又出现了,这次交换机的cpu也不高了,什么情况,一脸懵逼的状态。
再次排查,这次聚焦交换机,收集大量信息反馈给厂商,很快厂商给出的建议说是端口饱和丢包严重,影响了其他业务端口的正常使用,经过厂商进一步排查确认,该型号交换机虽然以前性能很好,但是已经属于老旧设备,该型号端口组背板能力只有1G,该组其他端口带宽总和已经超过了1G,属于交换机处理能力不足。
9)进一步协调该项目人员,调整大量交互端口成内网私有网段,单独使用一个千兆交换机做内部业务交互使用,外部访问还继续走这个交换机。最终这个问题得到解决。
总结:
此次事件引出三个问题:
1.端口绑定不可马虎,需要仔细再仔细,并做验证
2.预估业务端口网络流量不足,主机设备连线分配不合理
3.交换机老旧,处理能力不足
后续应该针对此类事情多多的总结,升级换代产品,深入了解业务特性
http://www.talkwithtrend.com/Article/178137
REDHAT和CENTOS 运维中网络知识汇总
http://www.talkwithtrend.com/Article/244015
下载 twt 社区客户端 APP
与更多同行在一起
高手随时解答你的疑难问题
轻松订阅各领域技术主题
浏览下载最新文章资料