当我们在互联网上浏览内容时,总会看到各种各样的图片,比如在你刷IT之家时,所看到的绝大部分图片都是JPG格式的,这种图片格式之所以在互联网上广受欢迎,是因为相比于PNG、GIF格式,它的体积相对较小,毕竟在上网时,用户希望图片加载得越快越好。
JPG格式的图片体积相对较小,是因为它采用了一系列的压缩算法,压缩图片弊端就是和原始的图片相比,它牺牲掉了一些画面细节,这些丢失的细节或许可被人的肉眼看出,或许以人的肉眼难以发现,对于这种通过牺牲画面的精细程度来达到缩小体积的目的的压缩算法,我们称之为“有损压缩”或者“破坏性压缩”,今天,IT之家就和大家聊聊JPEG图片压缩的基本原理。

JPEG和JPG的关系
很多读者可能会有这样的疑惑,JPEG和JPG看起来如此相像,它们到底是不是同一种图片格式?JPEG和JPG之间的关系到底是怎样的?在回答这个问题之前,我们首先要了解,JPEG的来头。
JPEG,全称为“Joint Photographic Experts Group”,翻译成中文,则是“联合图像专家小组”,这是一个成立于1986年的组织,1992年,该组织发布了“JPEG标准”,这是一种针对图像的压缩而制定的标准。
使用JPEG标准压缩的图片文件,被称为“JPEG文件”,这种文件的扩展名通常是JPG、JPEG、JPE、JFIF以及JIF,在这些文件格式中,以JPG的使用最为广泛。
如果这里JPEG指的是联合图像专家小组,那JPEG与JPG则是制定压缩标准的组织与采用该组织制定的压缩标准压缩成的图片的一种的格式的关系;
如果JPEG指的是JPEG压缩标准,那JPEG与JPG则是一种图像的压缩标准与采用该标准压缩成的图片的一种格式的关系;
如果JPEG指的是一张图片文件的后缀名,那JPEG与JPG的关系则是采用JPEG标准压缩的图片的两种不同的格式。
色彩空间转换
要压缩图片,首先要知道这个图片中都包含了些什么内容,在对图片的内容进行分解时,第一步就要进行色彩空间转换。
所谓的色彩空间,指的是描述图像的颜色的一组数值,比较常见的色彩空间有RGB、CMYK。
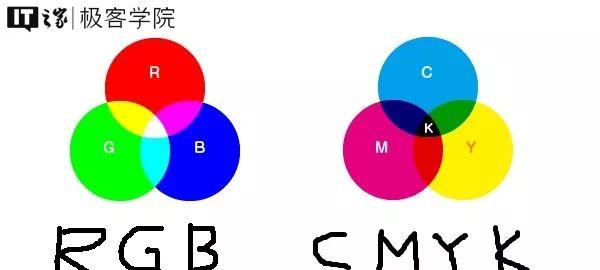
RGB,即是分别用三组数值,来表示红、绿、蓝,而红、绿、蓝三种颜色经过不同程度的配比,就会显示出不同的颜色。通常RGB的色彩模型用于显示屏的显示。
CMYK,即是分别用四组数值,来表示青色、品红、黄色和黑色,而青色、品红、黄色和黑色四种颜色经过不同程度的配比,就会显示出不同的颜色。通常CMYK的色彩模型用于印刷。
在JPEG压缩图像过程中,是怎么用数值来表示图像内容的呢?事实上,JPEG量化图像的颜色时并非采用RGB模式,也非CMYK模式,而是YCbCr模式,其中,Y表示的是亮度,Cb表示的是彩度(蓝),Cr表示的是彩度(红)。那么问题来了,为什么JPEG在压缩图像时,不采用RGB和CMYK的色彩模型,而偏偏采用YCbCr这种看似奇葩的模式呢?这还要从人眼的工作机制谈起。
我们的眼睛之所以能感知图像,是因为人眼内含有视锥细胞和视杆细胞,其中,视锥细胞具有感知颜色的能力,而视杆细胞具有感知亮度的能力,通常,我们的眼睛中,视杆细胞数量相对较多,所以人眼对亮度的敏感程度要高于对色彩的敏感程度。就像你熄灯时,你可以在暗光下渐渐地看清周围的事物,而对周围事物的颜色,你可能就不那么敏感了。
JPEG正是利用了人眼的这一特性,在压缩图像时,将亮度和颜色分开处理。

由于人眼对亮度很敏感,所以JPEG不会对亮度做太多改变,而人眼对颜色不甚敏感(科学研究表明,人眼大概可以区分出1000万种不同的颜色,这种感知能力相比于电脑,就没那么精确了),所以在人眼开始察觉色彩不对了之前,JPEG对颜色进行压缩处理,这样就算图像损失了部分细节,人眼也不太容易捕捉得到。
JPEG在压缩图像时所进行的色彩空间转换,指的就是将RGB转换为YCbCr。
缩减取样
在YCbCr模型中,Cb通道和Cr通道中所包含的信息量远远少于Y通道中包含的信息量,同时,人眼对色彩的敏感程度有限,因此,JPEG的压缩算法主要对Cb和Cr通道中的数据进行缩减取样,取样的比例可以是4:4:4(无缩减取样)、4:2:2(在水平方向2的倍数中取样)和4:2:0(在水平方向和垂直方向的2的倍数中取样),其中,以4:2:0最为常见。
离散余弦变换(DCT)
通常我们认为,在8*8像素的一块方格里,它里面的像素往往非常相似,因此,当进行到这一步时,JPEG会将图像分为一个又一个的8*8的像素块。

▲一个8*8的像素块,图片来自维基百科
每一个像素块都利用离散余弦变换来编码,法国数学家傅里叶告诉我们,几乎所有的周期函数,都可以用一系列的“弦波”来表示,也就是说,靠着带权重的一系列不同余弦值的相加,就可以重构出我们的原图。最后,每个8*8的像素块都会通过特定的函数,来生成一个新的8*8的数字矩阵。
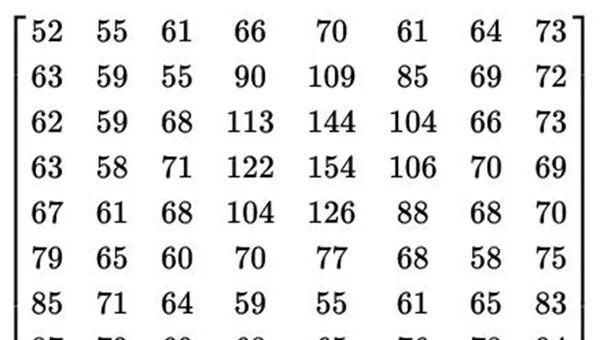
▲一个8*8的数字矩阵,图片来自维基百科
量化
事情到这里还没算完,通过离散余弦变换所得到的数字可不能被直接压缩,他们还需要再处理一下,这就是量化。
量化的过程,实际上就是对DTC系数的一个优化过程,在一个8*8像素的区域中,每个像素点间的差异都很大时,它的弦波频率就很高,我们称之为高频区,相反地,一个8*8像素的区域中,每个像素点间的差异很小,那它的弦波频率就很低,我们称之为低频区,刚刚的DCT算法已经把哪里频率高、哪里频率低给整理出来了。

▲越接近左上,频率越低,越接近右下,频率越高。
人眼对高频区(小范围、高复杂度)的辨识能力较差,而对低频区(大范围、低复杂度)的辨识能力较好,因此JPEG就根据人眼的这一特征将高频区进行大幅的简化和压缩,量化的过程,实际上就是把频率领域上的每个成分,除以一个特定的常数,然后将计算结果四舍五入,取一个整数,JPEG会将高频区的成分通过算法,使其接近于0,然后四舍五入,取该成分的值为0,最后,我们大概会得到这样一个矩阵:

可以看到,这个矩阵中有很多连续的0,这就对压缩非常有利了。
熵编码
终于到了最后一步了,那就是压缩,仔细观察刚刚得到的最终的矩阵,可以看到,从左上角到右下角,连续的0的数量急剧上升,这种情况就要用熵编码技术,对数据进行编码。
JPEG从左上角开始,以Z字形来回穿梭,直至经历了矩阵中的所有数字,到达右下角。
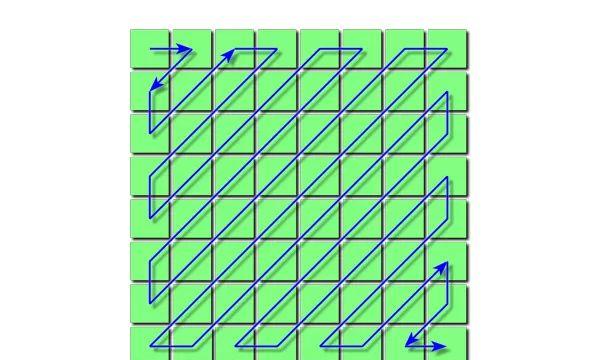
▲Z字形穿梭扫描的路径,图片来自维基百科
此时的编码就变成了这样:

当剩下的数字都是0,且过早结束的编码,可以将连续的0的部分采用霍夫曼编码表示为“EOB”,最后,这串编码就成了这个样子:
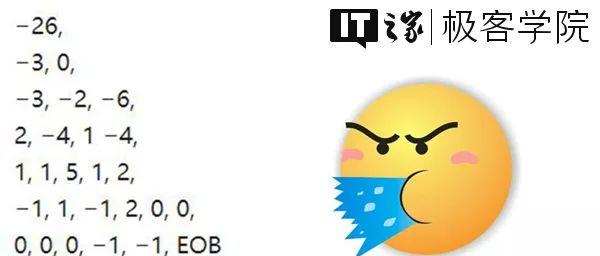
现在,我们就得到了JPEG的编码了。通过一系列的处理,可以看到,图像中的信息达到了压缩和简化的目的。这就是一幅原始图像被压缩为JPEG的大概过程。
图片质量
在生成一张JPG图像文件时,你通常需要设置图像质量参数,这个参数的数值越大,图像的质量也就越高,同时图片文件的体积也就越大,相反地,数值越小,图像的质量就越低,同时图片文件的体积越小,下面是三张图片:

▲图片一

▲图片二

▲图片三
第一张图片的质量参数是100,第二张图片的质量参数是60,第三张图片的质量参数是20,很容易可以看出,第一张图片的细节较为丰富,第二张图片的画面中好像稍微有一些噪点,第三章图片的直接可以看到大块的马赛克了。
代码示例
现在你已经了解了JPEG算法的工作原理,如果你想更进一步地学习,那么在GitHub中有这样一个代码示例,其作用就是进行JPEG压缩。
写在最后
这篇文章的目标受众是普通读者,出于浅显易懂的原则,这篇文章没有对数学算法进行深入讨论,也没有对数学定义进行严格阐述,如果你是相关领域的从业人员或者相关专业的高校学生,那么这篇文章可能不适合你。
在撰写这篇文章时,笔者参考了维基百科和相关技术博客中的一些知识,若文中有定义错误或者事实错误,还请不吝赐教。
相关文章精选:
中国三星,惊人的求生欲
道歉的抖音和不上道的抖音
鹅头大战!腾讯起诉头条这1元,是我见过最“贵”的1元
TNT工作站之后,坚果R1也要“理解万岁”了
高通骁龙710处理器正式发布!24678终于集齐
厉害!Lumia 950 XL成功运行Windows 10 ARM
惊现!微软Surface Phone及仙女座OS设备验证曝光