背景
HDFS 是 Hadoop 生态的默认存储系统,很多数据分析和管理工具都是基于它的 API 设计和实现的。但 HDFS 是为传统机房设计的,在云上维护 HDFS 一点也不轻松,需要投入不少人力进行监控、调优、扩容、故障恢复等一系列事情,而且还费用高昂,成本可能是对象存储是十倍以上。
在存储与计算分离大趋势下,很多人尝试用对象存储来构建数据湖方案,对象存储也提供了用于 Hadoop 生态的 connector,但因为对象存储自身的局限性,功能和性能都非常有限,在数据增长到一定规模后这些问题更加突出。
JuiceFS 正是为了解决这些问题而设计的,在保留对象存储的云原生特点的同时,更好地兼容 HDFS 的语义和功能,显著提升整体性能。本文以阿里云 OSS 为例,给大家介绍一下 JuiceFS 是如何全面提升对象存储在云上大数据场景中的表现的。
元数据性能
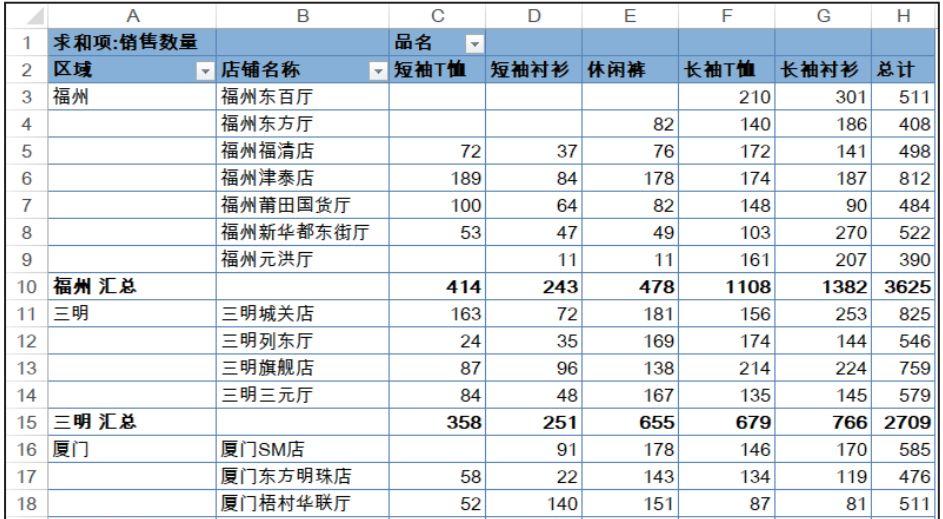
为了完整兼容 HDFS 并提供极致的元数据性能,JuiceFS 使用全内存的方式来管理元数据,将 OSS 作为数据存储使用,所有的元数据操作都不需要访问 OSS 以保证极致的性能和一致性。绝大部分元数据操作的响应时间都在 1ms 以内,而 OSS 通常要几十到一百毫秒以上。下面是使用 NNBench 进行元数据压测的结果:
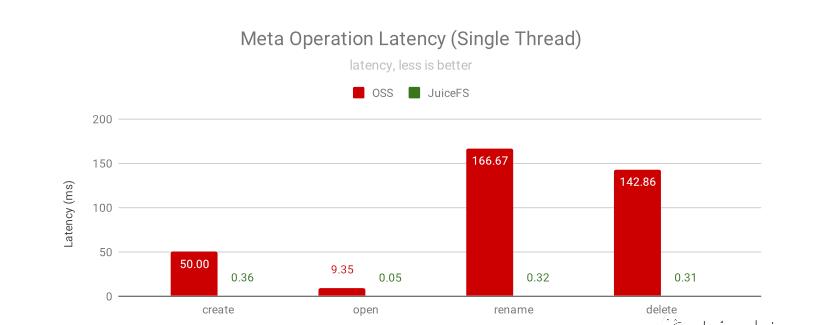
上图中的 rename 操作还只是针对单个文件的,因为它要拷贝数据所以很慢。在大数据实际的任务中通常是对目录做重命名,OSS 是 O(N) 复杂度,会随着目录里文件数量的增多限制变慢,而 JuiceFS 的 rename 的复杂度是 O(1) 的, 只是服务器端的一个原子操作,不管目录多大都可以一直这么快。
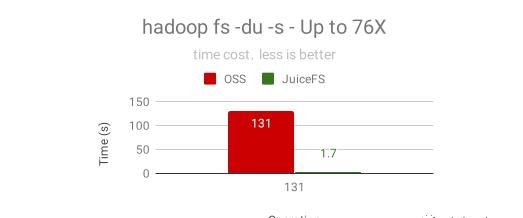
类似的还有 du 操作,它是要看一个目录里所有文件的总大小,在管理容量或者了解数据规模时非常有用。下图是对一个 100GB 数据(包含3949个子目录和文件)的目录做 du 的时间对比,JuiceFS 比 OSS 快 76倍!这是因为 JuiceFS 的 du 是基于服务器端内存中实时统计好的大小即时返回的,而 OSS 需要通过客户端遍历目录下的所有文件再累加求和,如果目录下的文件更多的话,性能差距会更大。
顺序读写性能
大数据场景有很多原始数据是以文本格式存储的,数据以追加方式写入,读取以顺序读为主(或者是顺序读其中一个分块)。在访问这类文件时,吞吐能力是一个关键指标。为了能够更好地支持这样的场景,JuiceFS 会先将它们切割成 64MB 的逻辑 Chunk,再分割成 4MB(可配置)的数据块写入对象存储,这样可以并发读写多个数据块以提升吞吐量。OSS 也支持分块上传,但有分块大小和分块数量的限制,而 JuiceFS 没有这些限制,单个文件可达 256PB。
同时,这类文本格式的文件还非常容易被压缩,JuiceFS 内置的 LZ4 或者 ZStandard 压缩算法可以在并行读写的同时进行压缩/解压缩,不但可以降低存储成本,还能减少网络流量,进一步提升顺序读写的性能。对于已经被压缩过的数据,这两个算法也能自动识别,避免重复的压缩。
再结合 JuiceFS 的智能预读和回写算法,很容易充分利用网络带宽和多核 CPU 的能力,将文本文件的处理性能推向极致。下图是单线程顺序 I/O 性能测试结果,显示了 JuiceFS 对大文件(使用不能被压缩的随机数据)的读写提速是非常显著的。
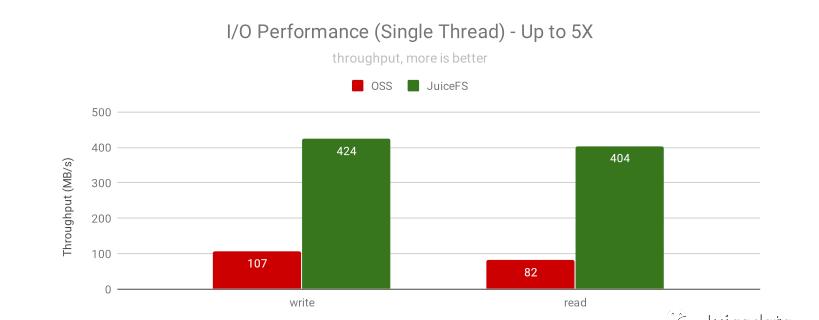
随机读性能
对于分析型数仓,通常会将原始数据经过清洗后使用更为高效的列存格式(Parquet 或者 ORC)来存储,一方面大幅节省存储空间,还能显著提升分析的速度。这些列存格式的数据,在访问模式上跟文本格式很不一样,以随机读居多,对存储系统的综合性能有更高的要求。
JuiceFS 针对这些列存格式文件的访问特点做了很多优化,将数据分块缓存到计算节点的 SSD 盘上是其中最核心的一点。为了保证缓存数据的正确性,JuiceFS 对所有写入的数据都使用唯一的 ID 来标识 OSS 中的数据块,并且永不修改,这样缓存的数据就不需要失效,只在空间不足时按照 LRU 算法清理即可。Parquet 和 ORC 文件通常只有局部列是热点,缓存整个文件或者一个 64MB 的 Chunk 会浪费空间,JuiceFS 采取的是以 1MB 分块(可配置)为单位的缓存机制。
计算集群中通常只会有一个缓存副本,通过一致性哈希算法来决定缓存的位置,并利用调度框架的本地优化机制来将计算任务调度到有数据缓存的节点,达到跟 HDFS 的数据本地化一样甚至更好的效果,因为 HDFS 的三个副本通常是随机调度的,操作系统页缓存的利用率会比较低,JuiceFS 的数据缓存会尽量调度到同一个节点,系统页缓存的利用率会更高。
当调度系统不能做本地化调度时,比如 SparkSQL 在读小文件时,会随机地把多个小文件合并到同一个任务中,就丧失了本地化特性,即使使用 HDFS 也是如此。JuiceFS 的分布式缓存很好地解决了这个问题,当计算任务未能调度到缓存所在节点时,JuiceFS 客户端会通过内部的 P2P 机制来访问缓存的数据,大幅提高缓存命中率和性能。
我们选取查询时间比较有代表性的 q2 来测试不同分块大小和缓存设置情况的加速效果:
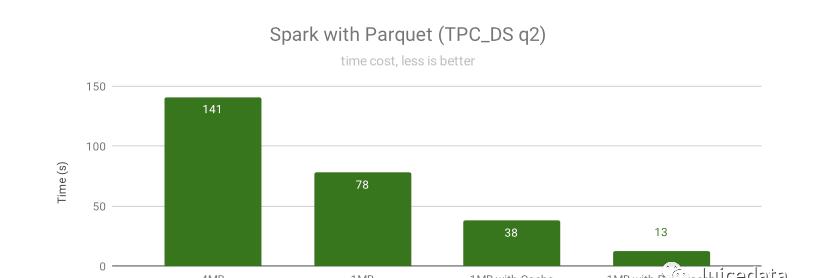
当没有启用缓存时,使用 1MB 的分块比 4MB 的分块性能更好,因为 4MB 的分块会产生更多的读放大,导致随机读变慢,也会浪费很多网络带宽导致网络拥堵。
启用缓存后,Spark 可以直接从缓存的数据块上做随机读,大大的提高了随机读性能。因为 SparkSQL 会将小文件随机合并到一个任务中,导致大部分文件没办法调度到有缓存的那个节点,缓存命中率很低,部分未命中缓存的读请求只能读对象存储,严重拖慢了整个任务。
在启用了分布式缓存后,不管计算任务调度到哪,JuiceFS 客户端都能够通过固定的节点读到缓存的速度,缓存命中率非常高,速度也非常快(通常第二次查询就能获得显著加速效果)。
JuiceFS 还支持随机写,但大数据场景不需要这个能力,OSS 也不支持,就不做对比了。
综合性能
TPC-DS 是大数据分析场景的典型测试集,我们用它来测试一下 JuiceFS 对 OSS 的性能提升效果,包括不同数据格式和不同分析引擎。
测试环境
我们在阿里云上使用 CDH 5.16 (估计是使用最为广泛的版本)搭建了一个集群,详细配置和软件版本如下:
Apache Spark 2.4.0.cloudera2ApacheImpala2.12Presto0.234OSS-Java-SDK3.4.1JuiceFSHadoopSDK0.6-betaMaster:4CPU32G内存,1台Slave:4CPU16G内存,200G高效云盘x2,3台Spark 参数:masteryarndriver-memory3gexecutor-memory9gexecutor-cores3num-executors3spark.locality.wait100spark.dynamicAllocation.enabledfalse
测试数据集使用 100GB 的 TPC-DS 数据集,多种存储格式和参数。完整跑完 99 条测试语句需要太多时间,我们选取了前面 10 条语句作为代表,已经包括各种类型的查询。
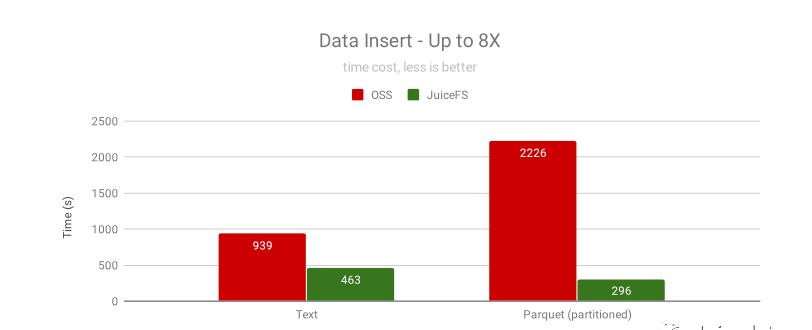
写入性能
通过读写同一张表来测试写入性能,使用的 SQL 语句是:
INSERT OVERWRITE store_sales SELECT * FROM store_sales;
我们对比了未分区的文本格式和按日期分区的 Parquet 格式,JuiceFS 都有显著性能提升,尤其是分区的 Parquet 格式。通过分析发现,OSS 花了很多时间在 Rename 上,它需要拷贝数据,还不能并发,而 Rename 在 JuiceFS 里是一个原子操作,瞬间完成。
SparkSQL 查询性能
Apache Spark 的使用非常广泛,我们使用 SparkSQL 来测试文本、Parquet 和 ORC 这 3 种文件格式下 JuiceFS 的提速效果,其中文本格式是未分区的,Parquet 和 ORC 格式是按照日期分区的。
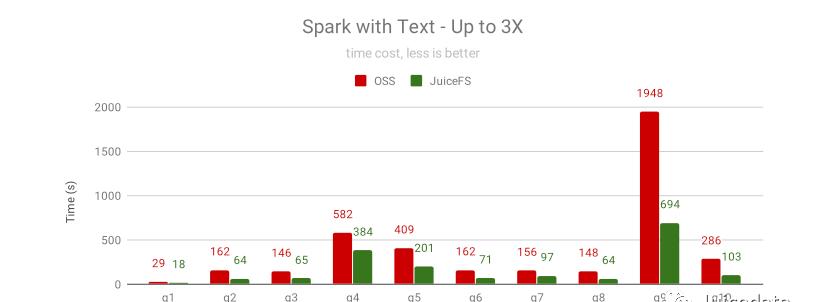
对于未分区的文本格式,需要扫描全部文本数据,主要瓶颈在 CPU,JuiceFS 的提速效果有限,最高能提升 3 倍。需要注意的是,如果使用 HTTPS 访问 OSS,Java 的 TLS 库比 JuiceFS 使用的 Go 的 TLS 库慢很多,同时 JuiceFS 对数据做了压缩,网络流量也会小很多,因此在两者都启用 HTTPS 来访问 OSS 时,JuiceFS 效果更好。
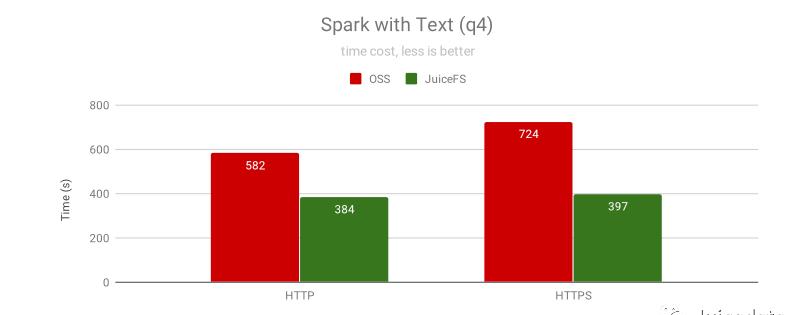
上图说明了在使用 HTTPS 的情况下,JuiceFS 的性能几乎没有变化,而 OSS 却
下降很多。
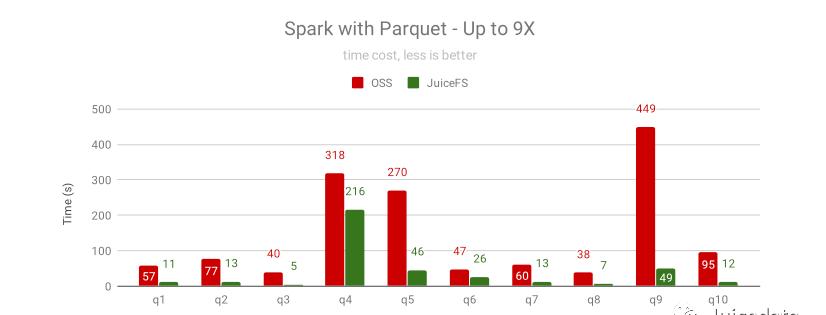
对于交互式查询,经常要对热点数据做反复查询的,上图是同一个查询重复 3 次后的结果,JuiceFS 依靠缓存的热点数据大幅提升性能,10 个查询中的 8 个有几倍的性能提升,提升幅度最少的 q4 也提升了 30%。
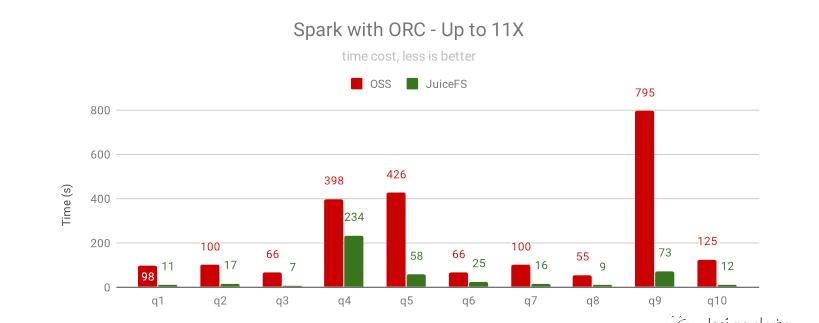
对 ORC 格式的数据集的提速效果跟 Parquet 格式类似,最高提速 11 倍,最少提速 40%。
对所有的数据格式,JuiceFS 都能显著提升 OSS 的查询性能,最高超过 10 倍。
Impala 查询性能
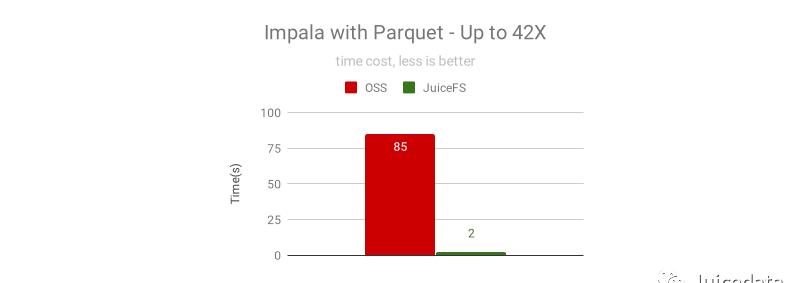
Impala 是性能非常好的交互分析引擎,对 I/O 本地化和 I/O 调度有非常好的优化,不需要使用 JuiceFS 的分布式缓存就能够获得很好的效果:为 OSS 提速 42倍!
Presto 是与 Impala 类似的查询引擎,但因为测试环境下配置的 OSS 不能跟 Presto 工作(原因未知),JuiceFS 没办法与 OSS 做比较。
总结
汇总上面的测试结果,JuiceFS 在所有场景中都能为 OSS 显著提速,当存储格式为 Parquet 和 ORC 这类列存格式时提速尤为明显,写入提升 8 倍,查询提升可达 10 倍以上。这显著的性能提升,不但节省了数据分析人员的宝贵时间,还能大幅减少计算资源的使用,降低成本。
以上只是以阿里云的 OSS 为实例做了性能对比,JuiceFS 的提速能力适用于所有云的对象存储,包括亚马逊的 S3、谷歌云的 GCS、腾讯云的 COS 等,也包括各种私有云或者自研的对象存储,JuiceFS 能显著提升它们在数据湖场景下的性能。此外,JuiceFS 还提供了更好的 Hadoop 兼容性(比如权限控制、快照等)和完整的 POSIX 访问能力,是云上数据湖的理想选择。