设为“置顶或星标”,第一时间送达干货
资料专栏
李航老师《统计学习方法(第二版)》课件&代码
【视频 PPT】李宏毅老师机器学习40讲
大家好,最近工作之余看了很多用户画像的文章,要么描述浅显、要么相对片面,对于数据分析人员来说算是窥中豹管。
一、 什么是用户画像
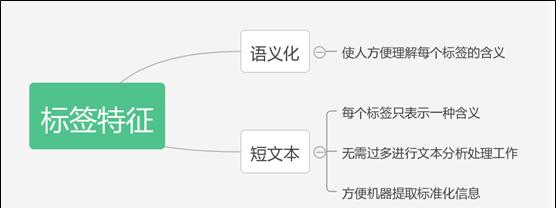
用户画像是指根据用户的属性、用户偏好、生活习惯、用户行为等信息而抽象出来的标签化用户模型。通俗说就是给用户打标签,而标签是通过对用户信息分析而来的高度精炼的特征标识。通过打标签可以利用一些高度概括、容易理解的特征来描述用户,可以让人更容易理解用户,并且可以方便计算机处理。
用户画像是对现实世界中用户的建模,用户画像应该包含目标,方式,组织,标准,验证这5个方面。
目标: 指的是描述人,认识人,了解人,理解人。
方式: 又分为非形式化手段,如使用文字、语言、图像、视频等方式描述人;形式化手段,即使用数据的方式来刻画人物的画像。
组织: 指的是结构化、非结构化的组织形式。
标准: 指的是使用常识、共识、知识体系的渐进过程来刻画人物,认识了解用户。

在产品早期和发展期,会较多地借助用户画像,帮助产品人员理解用户的需求,想象用户使用的场景,产品设计从为所有人做产品变成为三四个人做产品,间接的降低复杂度。
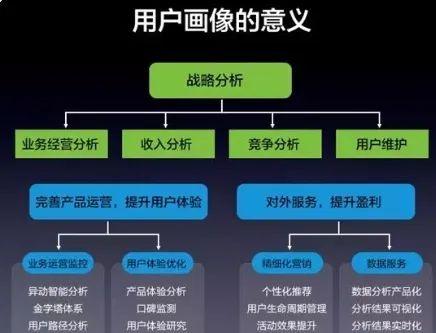
二、 用户画像的作用
在互联网、电商领域用户画像常用来作为精准营销、推荐系统的基础性工作,其作用总体包括:
(1)精准营销:根据历史用户特征,分析产品的潜在用户和用户的潜在需求,针对特定群体,利用短信、邮件等方式进行营销。
(2)用户统计:根据用户的属性、行为特征对用户进行分类后,统计不同特征下的用户数量、分布;分析不同用户画像群体的分布特征。
(3)数据挖掘:以用户画像为基础构建推荐系统、搜索引擎、广告投放系统,提升服务精准度。
(4)服务产品:对产品进行用户画像,对产品进行受众分析,更透彻地理解用户使用产品的心理动机和行为习惯,完善产品运营,提升服务质量。
(5)行业报告&用户研究:通过用户画像分析可以了解行业动态,比如人群消费习惯、消费偏好分析、不同地域品类消费差异分析
根据用户画像的作用可以看出,用户画像的使用场景较多,用户画像可以用来挖掘用户兴趣、偏好、人口统计学特征,主要目的是提升营销精准度、推荐匹配度,终极目的是提升产品服务,起到提升企业利润。用户画像适合于各个产品周期:从新用户的引流到潜在用户的挖掘、从老用户的培养到流失用户的回流等。
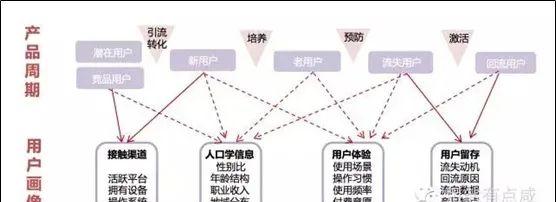
总结来说,用户画像必须从实际业务场景出发,解决实际的业务问题,之所以进行用户画像,要么是获取新用户,要么是提升用户体验、或者挽回流失用户等具有明确的业务目标。
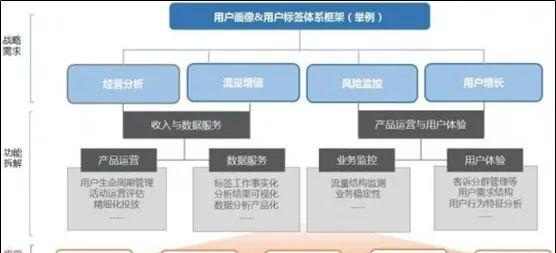
另外关于用户画像数据维度的问题,并不是说数据维度越丰富越好,总之,画像维度的设计同样需要紧跟业务实际情况进行开展。
三、 用户画像的分类
从画像方法来说,可以分为定性画像、定性 定量画像、定量画像
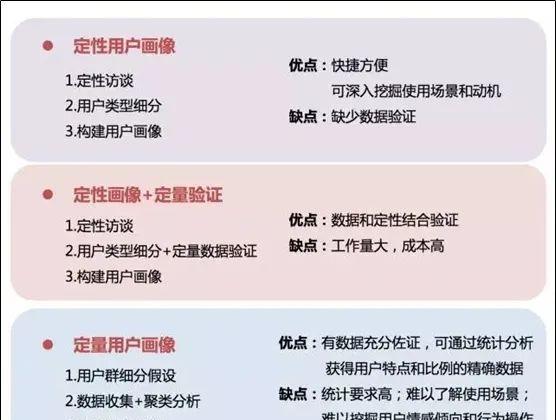
图片来自网络
从应用角度来看,可以分为行为画像、健康画像、企业信用画像、个人信用画像、静态产品画像、旋转设备画像、社会画像和经济画像等。
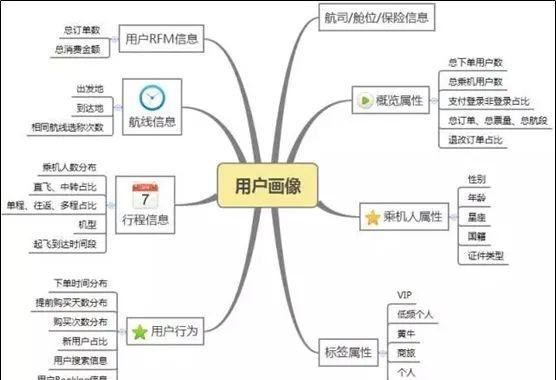
四、 用户画像需要用到哪些数据
一般来说,根据具体的业务内容,会有不同的数据,不同的业务目标,也会使用不同的数据。在互联网领域,用户画像数据可以包括以下内容:
(1)人口属性:包括性别、年龄等人的基本信息
(2)兴趣特征:浏览内容、收藏内容、阅读咨询、购买物品偏好等
(3)消费特征:与消费相关的特征
(4)位置特征:用户所处城市、所处居住区域、用户移动轨迹等
(5)设备属性:使用的终端特征等
(6)行为数据:访问时间、浏览路径等用户在网站的行为日志数据
(7)社交数据:用户社交相关数据

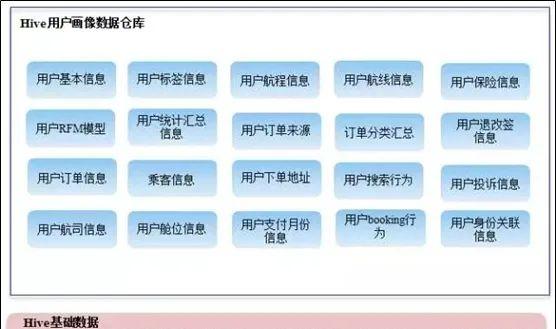
Qunar的画像数据仓库构建都是基于Qunar基础数据仓库构建,然后按照维度进行划分。
五、 用户画像主要应用场景
a)用户属性
b)用户标签画像
c)用户偏好画像
d)用户流失
e)用户行为
f)产品设计
g) 个性化推荐、广告系统、活动营销、内容推荐、兴趣偏好
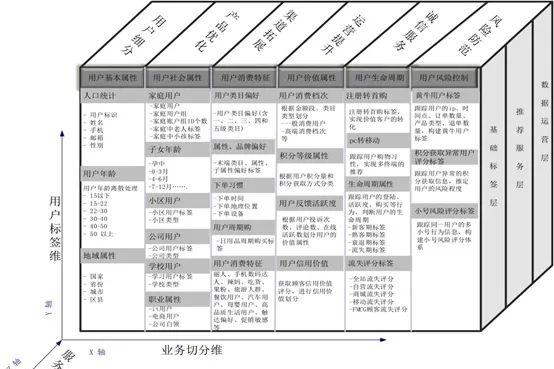
六、 用户画像使用的技术方法
历史文章已分享,不再赘述
七、 用户画像标签体系的建立1、什么是标签体系
用户画像是对现实用户做的一个数学模型,在整个数学模型中,核心是怎么描述业务知识体系,而这个业务知识体系就是本体论,本体论很复杂,我们找到一个特别朴素的实现,就是标签。
标签是某一种用户特征的符号表示。是一种内容组织方式,是一种关联性很强的关键字,能方便的帮助我们找到合适的内容及内容分类。(注:简单说,就是你把用户分到多少个类别里面去,这些类是什么,彼此之间有什么关系,就构成了标签体系)
标签解决的是描述(或命名)问题,但在实际应用中,还需要解决数据之间的关联,所以通常将标签作为一个体系来设计,以解决数据之间的关联问题。
一般来说,将能关联到具体用户数据的标签,称为叶子标签。对叶子标签进行分类汇总的标签,称为父标签。父标签和叶子标签共同构成标签体系,但两者是相对概念。例如:下表中,地市、型号在标签体系中相对于省份、品牌,是叶子标签。

用户画像标签体系创建后一般要包含以下几个方面的内容

(1)标签分类
用户画像标签可以分为基础属性标签和行为属性标签。
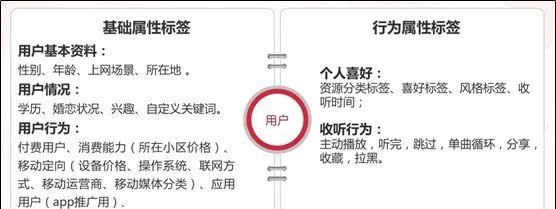
由于基于一个目标的画像,其标签是在动态扩展的,所以其标签体系也没有统一的模板,在大分类上,与自身的业务特征有很大的关联,在整体思路上可以从横纵两个维度展开思考:横向是产品内数据和产品外数据,纵向是线上数据和线下数据。而正中间则是永恒不变的“人物基础属性”。
如果说其他的分类因企业特征而定,那么只有人物特征属性(至于名字叫什么不重要,关键是内涵)是各家企业不能缺失的板块。
(2)标签级别(标签的体系结构)
分级有两个层面的含义,其一是:指标到最低层级的涵盖的层级;其二是指:指标的运算层级。其一非常好理解,这里重点说运算层级。
标签从运算层级角度可以分为三层:事实标签、模型标签、预测标签。
事实标签:是通过对于原始数据库的数据进行统计分析而来的,比如用户投诉次数,是基于用户一段时间内实际投诉的行为做的统计。
模型标签:模型标签是以事实标签为基础,通过构建事实标签与业务问题之间的模型,进行模型分析得到。比如,结合用户实际投诉次数、用户购买品类、用户支付的金额等,进行用户投诉倾向类型的识别,方便客服进行分类处理。
预测标签:则是在模型的基础上做预测,比如针对投诉倾向类型结构的变化,预测平台舆情风险指数。

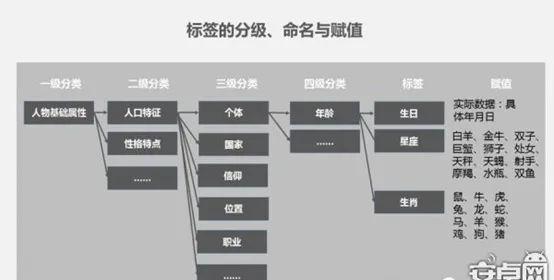
(3)标签命名&赋值
我们用一张图来说明一下命名和赋值的差别,只要在构建用户标签的过程种,有意识的区别标签命名和赋值足矣,不再赘述。
(4)标签属性
1、固有属性:是指这些指标的赋值体现的是用户生而有之或者事实存在的,不以外界条件或者自身认知的改变而改变的属性。比如:性别、年龄、是否生育等。
2、推导属性:由其他属性推导而来的属性,比如星座,我们可以通过用户的生日推导,比如用户的品类偏好,则可以通过日常购买来推导。
3、行为属性:产品内外实际发生的行为被记录后形成的赋值,比如用户的登陆时间,页面停留时长等。
4、态度属性:用户自我表达的态度和意愿。比如说我们通过一份问卷向用户询问一些问题,并形成标签,如询问用户:是否愿意结婚,是否喜欢某个品牌等。当然在大数据的需求背景下,利用问卷收集用户标签的方法效率显得过低,更多的是利用产品中相关的模块做了用户态度信息收集。
5、测试属性:测试属性是指来自用户的态度表达,但并不是用户直接表达的内容,而是通过分析用户的表达,结构化处理后,得出的测试结论。比如,用户填答了一系列的态度问卷,推导出用户的价值观类型等。

值得注意的是,一种标签的属性可以是多重的,比如:个人星座这个标签,既是固有属性,也是推导属性,它首先不以个人的意志为转移,同时可以通过身份证号推导而来。
即便你成功了建立用户画像的标签体系,也不意味着你就开启了用户画像的成功之路,因为有很大的可能是这些标签根本无法获得,或者说无法赋值。
标签无法赋值的原因有:数据无法采集(没有有效的渠道和方法采集到准确的数据,比如用户身份证号)、数据库不能打通、建模失败(预测指标无法获得赋值)等等。
2、标签体系结构
标签体系可以归纳出如下的层级结构。
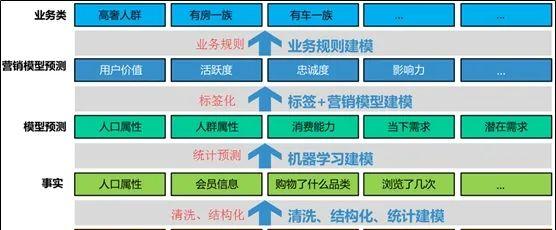
(1)原始输入层
主要指用户的历史数据信息,如会员信息、消费信息、网络行为信息。经过数据的清洗,从而达到用户标签体系的事实层。
(2)事实层
事实层是用户信息的准确描述层,其最重要的特点是,可以从用户身上得到确定与肯定的验证。如用户的人口属性、性别、年龄、籍贯、会员信息等。
(3)模型预测层
通过利用统计建模,数据挖掘、机器学习的思想,对事实层的数据进行分析利用,从而得到描述用户更为深刻的信息。如通过建模分析,可以对用户的性别偏好进行预测,从而能对没有收集到性别数据的新用户进行预测。还可以通过建模与数据挖掘,使用聚类、关联思想,发现人群的聚集特征。
(4)营销模型预测
利用模型预测层结果,对不同用户群体,相同需求的客户,通过打标签,建立营销模型,从而分析用户的活跃度、忠诚度、流失度、影响力等可以用来进行营销的数据。
(5)业务层
业务层可以是展现层。它是业务逻辑的直接体现,如图中所表示的,有车一族、有房一族等。
3、标签体系结构分类
一般来说,设计一个标签体系有3种思路,分别是:(1)结构化标签体系;(2)半结构化标签体系;(3)非结构化标签体系。
(1)结构化标签体系
简单地说,就是标签组织成比较规整的树或森林,有明确的层级划分和父子关系。结构化标签体系看起来整洁,又比较好解释,在面向品牌广告井喷时比较好用。性别、年龄这类人口属性标签,是最典型的结构化体系。下图就是Yahoo!受众定向广告平台采用的结构化标签体系。
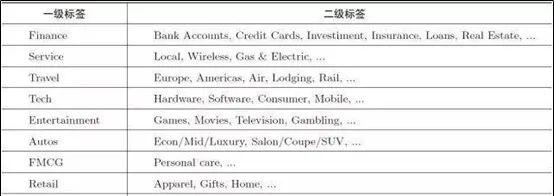
(2)半结构化标签体系
在用于效果广告时,标签设计的灵活性大大提高了。标签体系是不是规整,就不那么重要了,只要有效果就行。在这种思路下,用户标签往往是在行业上呈现出一定的并列体系,而各行业内的标签设计则以“逮住老鼠就是好猫”为最高指导原则,切不可拘泥于形式。下图是Bluekai聚合多家数据形成的半结构化标签体系。
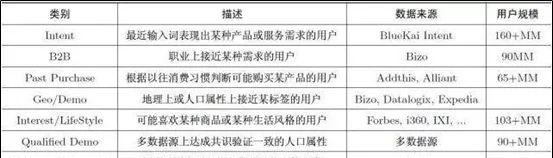
(3)非结构化标签体系
非结构化,就是各个标签就事论事,各自反应各自的用户兴趣,彼此之间并无层级关系,也很难组织成规整的树状结构。非结构化标签的典型例子,是搜索广告里用的关键词。还有Facebook用的用户兴趣词。
4、用户画像标签层级的建模方法
用户画像的核心是标签的建立,用户画像标签建立的各个阶段使用的模型和算法如下图所示。
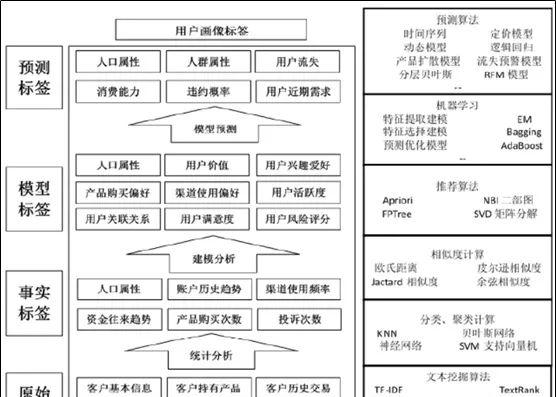
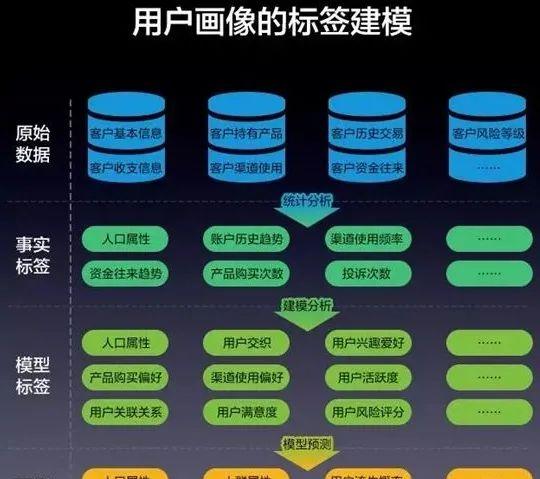
原始数据层
对原始数据,我们主要使用文本挖掘的算法进行分析如常见的TF-IDF、TopicModel主题模型、LDA 、深度学习等算法,主要是对原始数据的预处理和清洗,对用户数据的匹配和标识。
事实标签层
通过文本挖掘的方法,我们从数据中尽可能多的提取事实数据信息,如人口属性信息,用户行为信息,消费信息等。其主要使用的算法是分类和聚类。分类主要用于预测新用户,信息不全的用户的信息,对用户进行预测分类。聚类主要用于分析挖掘出具有相同特征的群体信息,进行受众细分,市场细分。对于文本的特征数据,其主要使用相似度计算,如余弦夹角,欧式距离等。
模型标签层
使用机器学习的方法,结合推荐算法。模型标签层完成对用户的标签建模与用户标识。其主要可以采用的算法有回归,决策树,支持向量机等。通过建模分析,我们可以进一步挖掘出用户的群体特征和个性权重特征,从而完善用户的价值衡量,服务满意度衡量等。
预测层
也是标签体系中的营销模型预测层。这一层级利用预测算法,如机器学习中的监督学习,计量经济学中的回归预测,数学中的线性规划等方法。实习对用户的流失预测,忠实度预测,兴趣程度预测等等,从而实现精准营销,个性化和定制化服务。
不同的标签层级会考虑使用对其适用的建模方法,对一些具体的问题,有专门的文章对其进行研究。
八、 用户画像基本步骤
根据具体业务规则确定用户画像方向后,开展用户画像分析,总体来说,一个用户画像流程包括以下三步。(1)用户画像的基本方向;(2)用户数据收集;(3)用户标签建模。

另外,需要注意的是用户画像的时效性,构建画像的数据多为历史数据,但用户的行为、偏好等特征多会随着时间的推移而发生变化。
九、 用户画像验证
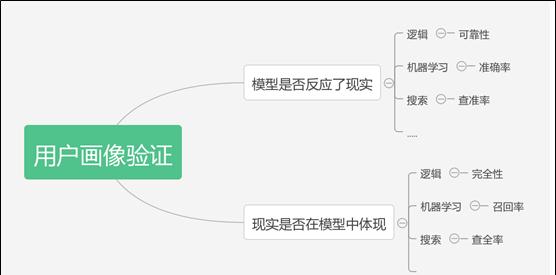
十、 用户画像的实际例子
注:此处涉及到工作中的项目内容,由于保密,就不能分享了
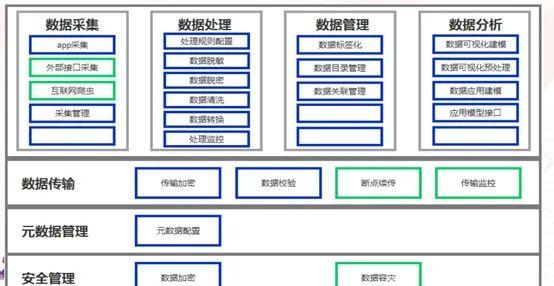
十一、 用户画像平台&架构
用户画像平台需要实现的功能。
用户画像系统技术架构
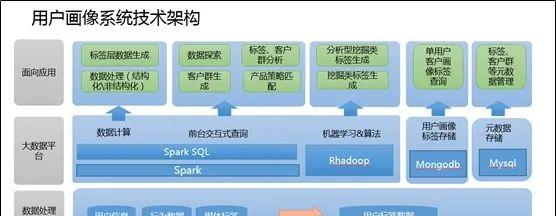
1、数据处理
b、通过hive编写UDF 或者hiveql根据业务逻辑拼接ETL,使用户对应上不同的用户标签数据(这里的指标可以理解为每个用户打上了相应的标签),生成相应的源表数据,以便于后续用户画像系统,通过不同的规则进行标签宽表的生成。
2、数据平台
a、数据平台应用的分布式文件系统为Hadoop的HDFS,因为Hadoop2.0以后,任何的大数据应用都可以通过ResoureManager申请资源,注册服务。比如(sparksubmit、hive)等等。而基于内存的计算框架的出现,就并不选用Hadoop的MapReduce了。当然很多离线处理的业务,很多人还是倾向于使用Hadoop,但是Hadoop封装的函数只有map和Reduce太过单一,而不像spark一类的计算框架有更多封装的函数(可参考博客spark专栏)。可以大大提升开发效率。
b、计算的框架选用Spark以及RHadoop,这里Spark的主要用途有两种,一种是对于数据处理与上层应用所指定的规则的数据筛选过滤,(通过Scala编写spark代码提交至sparksubmit)。一种是服务于上层应用的SparkSQL(通过启动spark thriftserver与前台应用进行连接)。RHadoop的应用主要在于对于标签数据的打分,比如利用协同过滤算法等各种推荐算法对数据进行各方面评分。
c、MongoDB内存数据的应用主要在于对于单个用户的实时的查询,也是通过对spark数据梳理后的标签宽表进行数据格式转换(json格式)导入mongodb,前台应用可通过连接mongodb进行数据转换,从而进行单个标签的展现。(当然也可将数据转换为Redis中的key value形式,导入Redis集群)
d、mysql的作用在于针对上层应用标签规则的存储,以及页面信息的展现。后台的数据宽表是与spark相关联,通过连接mysql随后cache元数据进行filter、select、map、reduce等对元数据信息的整理,再与真实存在于Hdfs的数据进行处理。
3、面向应用
从刚才的数据整理、数据平台的计算,都已经将服务于上层应用的标签大宽表生成。(用户所对应的各类标签信息)。那么前台根据业务逻辑,勾选不同的标签进行求和、剔除等操作,比如本月流量大于200M用户(标签) 本月消费超过100元用户(标签)进行和的操作,通过前台代码实现sql的拼接,进行客户数目的探索。这里就是通过jdbc的方式连接spark的thriftserver,通过集群进行HDFS上的大宽表的运算求count。(这里要注意一点,很多sql聚合函数以及多表关联join 相当于hadoop的mapreduce的shuffle,很容易造成内存溢出,相关参数调整可参考本博客spark栏目中的配置信息)这样便可以定位相应的客户数量,从而进行客户群、标签的分析,产品的策略匹配从而精准营销。
十二、用户画像困难点、用户画像瓶颈困难点
用户画像困难点主要表现为以下4个方面
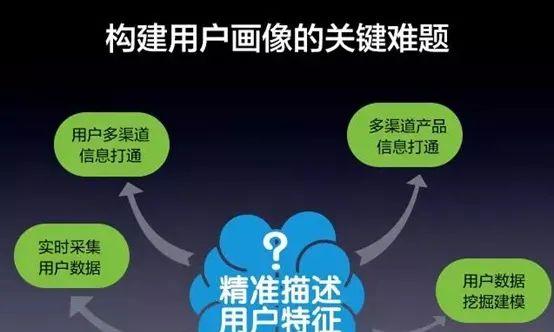
在画像之前需要知道产品的用户特征和用户使用产品的行为等因素,从而从总体上掌握对用户需求需求
创建用户画像不是抽离出典型进行单独标签化的过程,而是要融合边缘环境的相关信息来进行讨论
挑战
我们期间遇到了两方面的挑战:
1、亿级画像系统实践和应用
2、记录和存储亿级用户的画像,支持和扩展不断增加的维度和偏好,毫秒级的更新,支撑个公司性化推荐、广告投放和精细化营销等产品。