稿件:econometrics666@126.com
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.

关于相关计量方法视频课程,文章,数据和代码,参看1.面板数据方法免费课程, 文章, 数据和代码全在这里, 优秀学人好好收藏学习!2.双重差分DID方法免费课程, 文章, 数据和代码全在这里, 优秀学人必须收藏学习!3.工具变量IV估计免费课程, 文章, 数据和代码全在这里, 不学习可不要后悔!4.各种匹配方法免费课程, 文章, 数据和代码全在这里, 掌握匹配方法不是梦!5.断点回归RD和合成控制法SCM免费课程, 文章, 数据和代码全在这里, 有必要认真研究学习!6.空间计量免费课程, 文章, 数据和代码全在这里, 空间相关学者注意查收!7.Stata, R和Python视频课程, 文章, 数据和代码全在这里, 真的受用无穷!
正文


 该方法最初由Geweke引入,用于从多元截断的正态分布中计算随机变量。虽然它不能提供无偏的多元截断正态变量(如Ruud最初提出并由Borsch-Supan和Hajivassiliou(1990)详细说明的那样),但它确实产生了选择概率的无偏估计。在他们的研究中,累积分布函数被假定为是多元正太的,并由协方差矩阵M确定。这个方法是快速的,并产生平稳依赖参数和M的提取和模拟概率。后一种依赖使人们能够使用传统的数值方法,如二次山丘或梯度方法来解决一阶条件,使模拟似然函数(方程(7))在q = 1,2,…的样本个体中最大化,由此得到最大模拟似然(MSL)。 经过模型估计,有很多结果需要解释。先说好,参数估计通常从随机参数或误差组件规范中获得,不应被解释为独立的参数,而必须与其他关联的参数估计联合评估。例如,旅行时间的边际效用是平均参数、旅行长度的允许值和个体间变化的随机项的函数。这个最一般的公式将在适当考虑随机参数的分布假设的情况下写出。 到目前为止,规范已经假定备选方案的属性是独立的。如果我们允许属性(即选项)相关,那么前面的随机部分将被替换为几个参数的随机部分的混合物。 由此,对混合logit模型的概述提供了一个框架,在这个框架中,我们可以研究一些具有实际意义的重要问题。我们把它们确定为七个重要的实证项目:
该方法最初由Geweke引入,用于从多元截断的正态分布中计算随机变量。虽然它不能提供无偏的多元截断正态变量(如Ruud最初提出并由Borsch-Supan和Hajivassiliou(1990)详细说明的那样),但它确实产生了选择概率的无偏估计。在他们的研究中,累积分布函数被假定为是多元正太的,并由协方差矩阵M确定。这个方法是快速的,并产生平稳依赖参数和M的提取和模拟概率。后一种依赖使人们能够使用传统的数值方法,如二次山丘或梯度方法来解决一阶条件,使模拟似然函数(方程(7))在q = 1,2,…的样本个体中最大化,由此得到最大模拟似然(MSL)。 经过模型估计,有很多结果需要解释。先说好,参数估计通常从随机参数或误差组件规范中获得,不应被解释为独立的参数,而必须与其他关联的参数估计联合评估。例如,旅行时间的边际效用是平均参数、旅行长度的允许值和个体间变化的随机项的函数。这个最一般的公式将在适当考虑随机参数的分布假设的情况下写出。 到目前为止,规范已经假定备选方案的属性是独立的。如果我们允许属性(即选项)相关,那么前面的随机部分将被替换为几个参数的随机部分的混合物。 由此,对混合logit模型的概述提供了一个框架,在这个框架中,我们可以研究一些具有实际意义的重要问题。我们把它们确定为七个重要的实证项目:
选择随机参数;
选择随机参数的分布;
选择分布中点的数量;
随机参数平均值附近的参数异质性;
考虑从同一个个体中获得的观测值:相关选择的情况;
考虑参数之间的关联;
支付困难的意愿。
在宽阔道路上自由流动的时间(分钟)
在宽阔道路上被其他车辆拖慢的时间(以分钟计)
在开放道路上与紧随其后的车辆在一起的总时间所占百分比(%)
道路的弯曲(有四层属性,几乎是直的,轻微的,中等的,蜿蜒的)
运营成本(美元)
通行费(美元)
这六个属性有四个层次,我们选择如下:自由流动旅行时间:20%,10%, 10%, 20%时间变慢:20%,10%, 10%, 20%车辆紧跟的时间百分比:50%,25%, 25%, 50%曲度:几乎直,轻微,中等,弯曲运行成本:10%,5%, 5%, 10%如果行驶时间为:小汽车的通行费($),卡车的通行费加倍:1小时或少于0,0.5,1.5,31小时到2小时30分钟0,1.5,4.5,9超过2个半小时0 2.5 7.5 15个小时
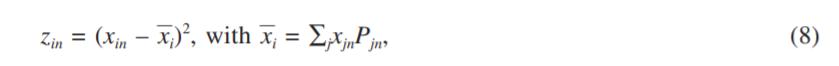 这里边
这里边
 。4.2.3 对数正态分布 对数正态分布在下面的推理中很常用。中心极限定理解释了正态曲线的起源。如果大量的随机冲击(有些是正的,有些是负的)以加法的方式改变了特定属性x的大小,那么随着冲击数量的增加,该属性的分布将趋向于变成正态分布。但是,如果这些冲击是乘数作用的,通过随机分布的比例而不是绝对数量改变x的值,中心极限定理应用于Y = ln(x)趋向于产生一个正态分布。因此x是对数正态分布。对加法随机冲击的乘法替代产生一个正偏的、轻峰的、对数正态分布,而不是一个对称的正态分布。双参数对数正态分布的偏度和峰度只依赖于正态分布的方差,如果方差足够低,对数正态分布就近似于正态分布。对数法线的吸引力在于它们被限制在非负域内;然而,它们通常有一个很长的右尾,这是一个缺点(尤其是在计算意愿支付时)。正是这种“不合理”的价值所占比例如此之大,常常让人怀疑对数正态分布是否恰当。在参数估计中,经验表明,进入一个属性在一个实用表达式指定使用一个随机参数对数正态分布,并预计先验产生负面的意思估计,通常会导致模型不收敛或收敛与不可接受大意味着估计。克服这个问题的技巧是在模型估计之前将属性的符号反转(即定义属性的负数,而不是对估计的参数施加符号变化)。其逻辑如下。对数法线只有在正数时才有非零密度。因此,为了确保一个属性对于所有被采样的个体都有一个负数参数,必须输入该属性的负数。负属性的正对数正态参数与属性本身的负对数正态参数相同。4.2.4 为分布增加约束在实践中,我们经常发现任何一种分布都有优点和缺点。弱点通常与分布在其极端处的扩展或标准偏差有关,包括对对称分布的行为上不可接受的符号变化。对数正态分布有一条长长的上尾。由于标准偏差的关系,法向、均匀和三角形可能会给某些参数带来错误的符号。一个吸引人的解决方案是使每个随机参数的散布或标准偏差成为平均值的函数。例如,根据正态分布,通常的规范是定义
。4.2.3 对数正态分布 对数正态分布在下面的推理中很常用。中心极限定理解释了正态曲线的起源。如果大量的随机冲击(有些是正的,有些是负的)以加法的方式改变了特定属性x的大小,那么随着冲击数量的增加,该属性的分布将趋向于变成正态分布。但是,如果这些冲击是乘数作用的,通过随机分布的比例而不是绝对数量改变x的值,中心极限定理应用于Y = ln(x)趋向于产生一个正态分布。因此x是对数正态分布。对加法随机冲击的乘法替代产生一个正偏的、轻峰的、对数正态分布,而不是一个对称的正态分布。双参数对数正态分布的偏度和峰度只依赖于正态分布的方差,如果方差足够低,对数正态分布就近似于正态分布。对数法线的吸引力在于它们被限制在非负域内;然而,它们通常有一个很长的右尾,这是一个缺点(尤其是在计算意愿支付时)。正是这种“不合理”的价值所占比例如此之大,常常让人怀疑对数正态分布是否恰当。在参数估计中,经验表明,进入一个属性在一个实用表达式指定使用一个随机参数对数正态分布,并预计先验产生负面的意思估计,通常会导致模型不收敛或收敛与不可接受大意味着估计。克服这个问题的技巧是在模型估计之前将属性的符号反转(即定义属性的负数,而不是对估计的参数施加符号变化)。其逻辑如下。对数法线只有在正数时才有非零密度。因此,为了确保一个属性对于所有被采样的个体都有一个负数参数,必须输入该属性的负数。负属性的正对数正态参数与属性本身的负对数正态参数相同。4.2.4 为分布增加约束在实践中,我们经常发现任何一种分布都有优点和缺点。弱点通常与分布在其极端处的扩展或标准偏差有关,包括对对称分布的行为上不可接受的符号变化。对数正态分布有一条长长的上尾。由于标准偏差的关系,法向、均匀和三角形可能会给某些参数带来错误的符号。一个吸引人的解决方案是使每个随机参数的散布或标准偏差成为平均值的函数。例如,根据正态分布,通常的规范是定义

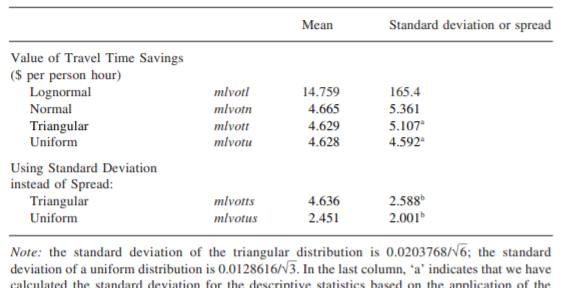 图表 2其中tripl是以分钟为单位的行程长度,60是美元/分钟到美元/小时的换算,n是标准正态分布,u是均匀分布,t是三角形分布。每个个体的VTTS被重复(250)随机抽取
图表 2其中tripl是以分钟为单位的行程长度,60是美元/分钟到美元/小时的换算,n是标准正态分布,u是均匀分布,t是三角形分布。每个个体的VTTS被重复(250)随机抽取
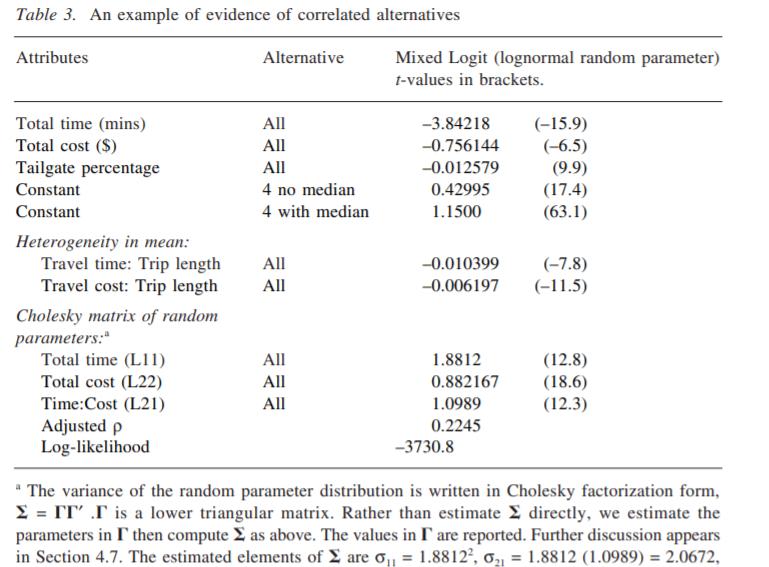
 , t和uc估计,并导出平均值和标准偏差(或扩散)。正态矩、三角矩和均匀矩非常相似(包括未报告的相关模型的总体拟合优度);对数正态分布明显不同于难以接受的大标准差。然而,对数正态分布保证了VTTS非负的,而其他三个(无约束分布)几乎肯定意味着一些负的VTTS,如图4所示。在本应用中,法线、三角线和均匀线的负VTTS百分比分别为19.21%、39.33%和37.92%。这些百分比是由VTTS的累积频率分布得到的。
, t和uc估计,并导出平均值和标准偏差(或扩散)。正态矩、三角矩和均匀矩非常相似(包括未报告的相关模型的总体拟合优度);对数正态分布明显不同于难以接受的大标准差。然而,对数正态分布保证了VTTS非负的,而其他三个(无约束分布)几乎肯定意味着一些负的VTTS,如图4所示。在本应用中,法线、三角线和均匀线的负VTTS百分比分别为19.21%、39.33%和37.92%。这些百分比是由VTTS的累积频率分布得到的。
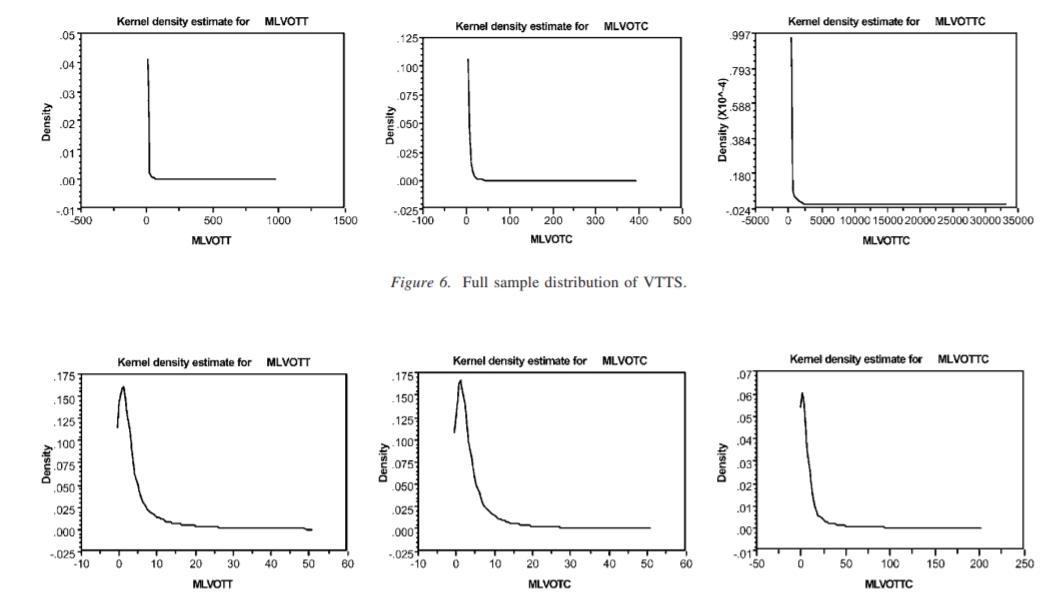
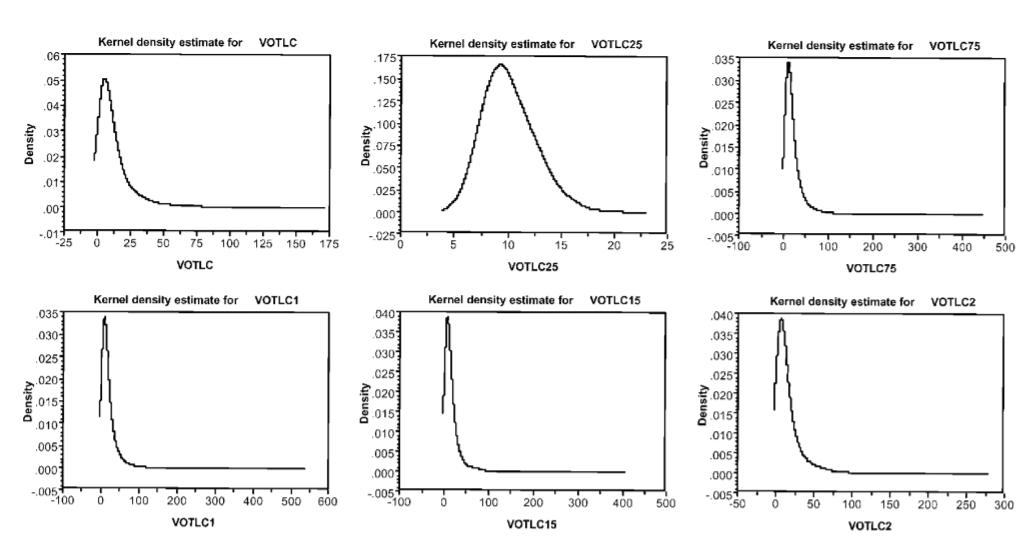
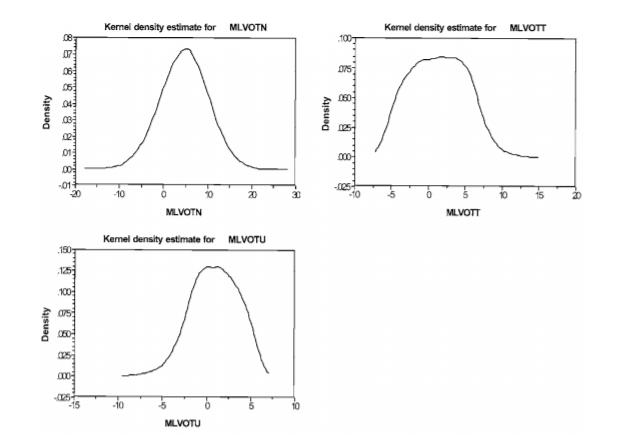 图表 34.2.7 揭示经验分布,以协助寻找解析分布 如上所述,选择具有理想行为特性的分析分布并不是一项容易的任务。实际上,真实的分布可能是双模态或多模态,结果是没有一个流行的分布是合适的。考虑到为随机参数选择合适的分析分布的不确定性,经验的观点可能是有用的。也就是说,我们能否通过参考个体层面的参数估计来告知分布的选择?这包括为每个抽样个体建立唯一的(平均)参数估计,然后绘制分布图(简单地计算一个标准差或分布不能揭示分布的形状)。为了说明这一点,给定一个足够丰富的数据集(如数据集2),其中我们对每个抽样个体有多个观察(在陈述的选择实验中很常见),我们可能会估计使用16个选择情况的每个抽样个体的多项式logit模型。可以使用核密度(在下面和Greene 2002年定义)非参数地绘制出派生的特定参数估计值,以揭示其在抽样总体上的分布信息。检查个人特定参数的经验分布提供了关于结构和方法的线索,这种结构可能被合并回一个混合logit模型。然而,根据经验建立真实分布是一个挑战,因为在真实数据中可能存在偏差,无论是揭示的还是陈述的选择数据。当要估计特定个体的模型时,在选择情况下属性水平的可变性变得更加关键。可变率有限的指定选择设计(特别是当可变率相对于当前选择是一个固定的范围)会在实现渐近有效的参数估计方面产生问题。在使用一些选择情况下的单个个体数据估计的模型中,发现大得不能接受的t值和错误的符号是很常见的。例如,在对16种选择情况和10个自由度估计的单个模型的数据集2中,高达80%的抽样个体有一个参数在统计上不显著(有时包括一个错误的符号)。我们怀疑这在很大程度上是在陈述的选择实验中所提供的属性水平有限的可变性的产物,在个体受访者水平的选择情境中。改进的可变性可以通过许多策略来实现,例如在大范围内增加级别的数量,以及在选择情况下对具有公共级别数(例如4个级别)的给定属性的可选属性范围进行抽样。如果可以建立商定的分割标准(如行程长度、个人收入),也可以通过汇集个人子集来适应。选择合适的策略很复杂,而且研究不足。我们提出的方法包括估计Q 1模型(其中Q是样本中的143个个体)。除了一个涉及整个样本的模型外,其他每个模型都是通过去除一个不同的个体来区分的。参数的数值的差异估计模型基于全部样本(143)和基于142人提供了每个模型的贡献(增量边际效用)的一个特定的个体样本均值的总体参数估计,因而是个人偏好异质性的概要文件。数据集2用来说明这个过程。我们绘制了143个模型的参数估计矩阵,以建立每个属性的边际效用(即偏好异质性)的经验剖面。核密度估计器是一种有用的方法,因为它可以非参数地描述参数的分布,也就是说,不需要对基本的解析分布作任何假设。核密度是人们熟悉的直方图的一种修改,直方图用于图形化地描述观测样本的分布。核估计器克服了直方图的缺点,首先直方图是不连续的,而(我们的模型假设)基础分布是连续的,其次,直方图的形状关键取决于假设的宽度和箱子的位置。直觉告诉我们,使用更窄的箱子可以减轻第一个问题,但这样做的代价是,每个箱子里的观测数量下降,因此直方图所描绘的更大的图像变得越来越不稳定和不精确。核密度估计器是一个平滑的图,它显示了对于每一个选定的点,在它附近的样本的比例。(因此得名密度)近度是由一个称为核函数的权值函数定义的,它的特征是,样本观测距离所选点越远,所获得的权值就越小。单个属性的核密度函数使用以下公式计算:
图表 34.2.7 揭示经验分布,以协助寻找解析分布 如上所述,选择具有理想行为特性的分析分布并不是一项容易的任务。实际上,真实的分布可能是双模态或多模态,结果是没有一个流行的分布是合适的。考虑到为随机参数选择合适的分析分布的不确定性,经验的观点可能是有用的。也就是说,我们能否通过参考个体层面的参数估计来告知分布的选择?这包括为每个抽样个体建立唯一的(平均)参数估计,然后绘制分布图(简单地计算一个标准差或分布不能揭示分布的形状)。为了说明这一点,给定一个足够丰富的数据集(如数据集2),其中我们对每个抽样个体有多个观察(在陈述的选择实验中很常见),我们可能会估计使用16个选择情况的每个抽样个体的多项式logit模型。可以使用核密度(在下面和Greene 2002年定义)非参数地绘制出派生的特定参数估计值,以揭示其在抽样总体上的分布信息。检查个人特定参数的经验分布提供了关于结构和方法的线索,这种结构可能被合并回一个混合logit模型。然而,根据经验建立真实分布是一个挑战,因为在真实数据中可能存在偏差,无论是揭示的还是陈述的选择数据。当要估计特定个体的模型时,在选择情况下属性水平的可变性变得更加关键。可变率有限的指定选择设计(特别是当可变率相对于当前选择是一个固定的范围)会在实现渐近有效的参数估计方面产生问题。在使用一些选择情况下的单个个体数据估计的模型中,发现大得不能接受的t值和错误的符号是很常见的。例如,在对16种选择情况和10个自由度估计的单个模型的数据集2中,高达80%的抽样个体有一个参数在统计上不显著(有时包括一个错误的符号)。我们怀疑这在很大程度上是在陈述的选择实验中所提供的属性水平有限的可变性的产物,在个体受访者水平的选择情境中。改进的可变性可以通过许多策略来实现,例如在大范围内增加级别的数量,以及在选择情况下对具有公共级别数(例如4个级别)的给定属性的可选属性范围进行抽样。如果可以建立商定的分割标准(如行程长度、个人收入),也可以通过汇集个人子集来适应。选择合适的策略很复杂,而且研究不足。我们提出的方法包括估计Q 1模型(其中Q是样本中的143个个体)。除了一个涉及整个样本的模型外,其他每个模型都是通过去除一个不同的个体来区分的。参数的数值的差异估计模型基于全部样本(143)和基于142人提供了每个模型的贡献(增量边际效用)的一个特定的个体样本均值的总体参数估计,因而是个人偏好异质性的概要文件。数据集2用来说明这个过程。我们绘制了143个模型的参数估计矩阵,以建立每个属性的边际效用(即偏好异质性)的经验剖面。核密度估计器是一种有用的方法,因为它可以非参数地描述参数的分布,也就是说,不需要对基本的解析分布作任何假设。核密度是人们熟悉的直方图的一种修改,直方图用于图形化地描述观测样本的分布。核估计器克服了直方图的缺点,首先直方图是不连续的,而(我们的模型假设)基础分布是连续的,其次,直方图的形状关键取决于假设的宽度和箱子的位置。直觉告诉我们,使用更窄的箱子可以减轻第一个问题,但这样做的代价是,每个箱子里的观测数量下降,因此直方图所描绘的更大的图像变得越来越不稳定和不精确。核密度估计器是一个平滑的图,它显示了对于每一个选定的点,在它附近的样本的比例。(因此得名密度)近度是由一个称为核函数的权值函数定义的,它的特征是,样本观测距离所选点越远,所获得的权值就越小。单个属性的核密度函数使用以下公式计算:

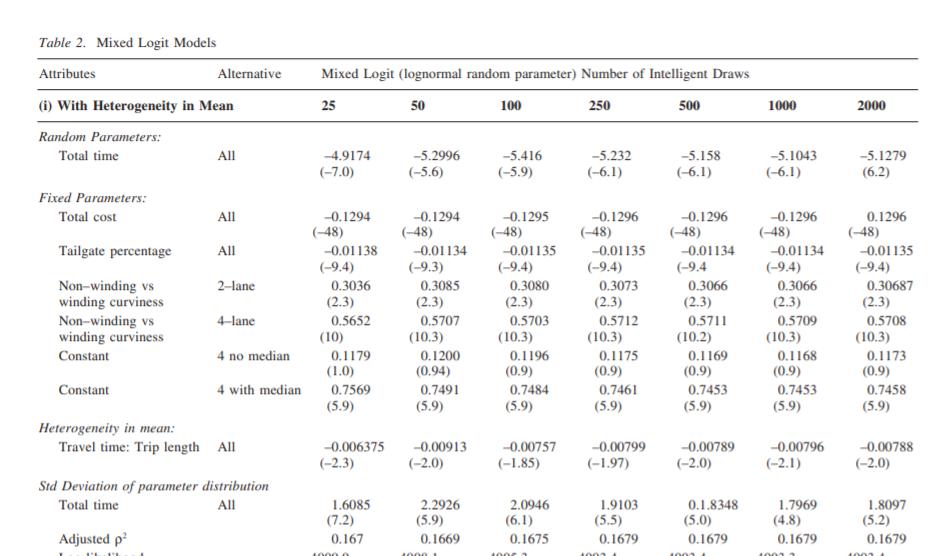
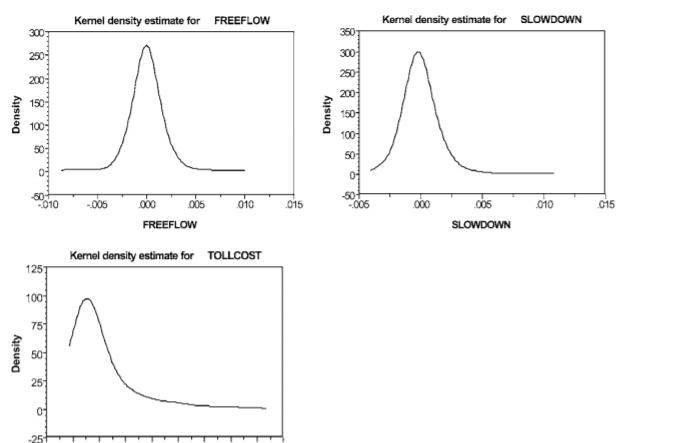 图表 44.3 为仿真选择点的数目保证平稳的参数估计集合所需要的提取次数存在巨大差异。一般来说,似乎随着模型的形式在随机参数的数量和围绕均值的偏好异质性的处理,以及属性和选项之间的关联方面变得复杂,给定形式的抽取(例如Halton智能抽取)所需的次数也会增加。并没有一个标准的数,不过经验表明,最低25次智能抽取,能让有三个选择和一到两个参数(性质之间没有关联,均值附近的异质性没有分解)的选择模型产生稳定性,尽管100看起来是个不错的数字。然而,最好的测试是用一组数字来估计模型(25,50,100,1000,2000这样的抽取)。每一种模型的稳定性/精度的确定是非常重要的。只有一个随机参数的下表提供了143个个体从25到2000个经验分布的一系列运行(数据集2)。智能绘图(数据集1中的汽车司机)。结果在大约500次绘图后稳定下来,这可能是多余的,特别是考虑到只有一个维度的集成。给定在比较模型参数估计的通常尺度考虑,为随机参数,总时间的平均值对其标准差的比率,是在显示如何稳定分布的前两个时刻的关系的稳定性的信息。在这个应用程序中,整个绘图范围的比率范围非常相似,不会对分布的形状或分布的某些不可接受的变化发出警报。在推导支付意愿指标(如VTTS)的经验分布时,这一点尤为重要。有人可能会问,为什么分析人员不简单地选择更大数量的抽取,以认识到更大的可能性,从而达到适当的稳定参数估计集?较少的绘图数量是一个相关的考虑因素,其本质上是在大量的绘图中,在估计首选模型之前,相对快速地探索替代模型规范的能力。即使使用快速的计算机,它也可能需要花费数小时的运行时间,其中包含许多随机参数、大样本大小和数千次绘图。知道参数稳定性什么时候出现问题具有极大的实用价值,使分析人员能够在一个不太可能误导推理过程的绘制域中寻找改进的模型。Bhat(2001)和Train(1999)发现,使用100个Halton数估计参数的模拟方差低于1000个随机数。在125次霍尔顿抽取中,他们都发现模拟错误是1000次随机抽取的一半,比2000次随机抽取的小。估计过程要快得多(通常快10倍)。Hensher(2000)研究了涉及10、25、50、100、150和200次抽取的Halton序列(带有三个随机泛型参数),并在VTTS环境下与随机抽取进行了比较。在所有被研究的模型中,Hensher得出结论,少量的draw(低至25)产生的模型吻合度和平均VTTS几乎无法区分。这是复杂选择模型估计方面的一个显著发展。然而,在我们确定我们已经找到了最好的抽签策略之前,研究人员正在发现其他可能更好。例如,Sandor和Train(2002)对random、Halton、Niederreiter和正交数组抽取的研究发现,纯随机抽取的结果常常令人困惑,有时表现得比它们应该做的好得多,有时各种类型的抽取都比它们应该做的差得多。在估计的模拟方差中我们遗漏了什么?也许是由于优化算法不同的估计不同的绘图?最近Bhat对积分维数绘制类型的研究(已出版)表明,由于高维数序列的相关性,标准霍尔顿序列的均匀性在高维数中被打破。Bhat提出了一种打乱这些相关性的版本,以及一种计算方差估计的随机版本。这些最近研究的例子证明了对模拟绘图进行持续调查的必要性,特别是当强加分布的属性数量增加时。
图表 44.3 为仿真选择点的数目保证平稳的参数估计集合所需要的提取次数存在巨大差异。一般来说,似乎随着模型的形式在随机参数的数量和围绕均值的偏好异质性的处理,以及属性和选项之间的关联方面变得复杂,给定形式的抽取(例如Halton智能抽取)所需的次数也会增加。并没有一个标准的数,不过经验表明,最低25次智能抽取,能让有三个选择和一到两个参数(性质之间没有关联,均值附近的异质性没有分解)的选择模型产生稳定性,尽管100看起来是个不错的数字。然而,最好的测试是用一组数字来估计模型(25,50,100,1000,2000这样的抽取)。每一种模型的稳定性/精度的确定是非常重要的。只有一个随机参数的下表提供了143个个体从25到2000个经验分布的一系列运行(数据集2)。智能绘图(数据集1中的汽车司机)。结果在大约500次绘图后稳定下来,这可能是多余的,特别是考虑到只有一个维度的集成。给定在比较模型参数估计的通常尺度考虑,为随机参数,总时间的平均值对其标准差的比率,是在显示如何稳定分布的前两个时刻的关系的稳定性的信息。在这个应用程序中,整个绘图范围的比率范围非常相似,不会对分布的形状或分布的某些不可接受的变化发出警报。在推导支付意愿指标(如VTTS)的经验分布时,这一点尤为重要。有人可能会问,为什么分析人员不简单地选择更大数量的抽取,以认识到更大的可能性,从而达到适当的稳定参数估计集?较少的绘图数量是一个相关的考虑因素,其本质上是在大量的绘图中,在估计首选模型之前,相对快速地探索替代模型规范的能力。即使使用快速的计算机,它也可能需要花费数小时的运行时间,其中包含许多随机参数、大样本大小和数千次绘图。知道参数稳定性什么时候出现问题具有极大的实用价值,使分析人员能够在一个不太可能误导推理过程的绘制域中寻找改进的模型。Bhat(2001)和Train(1999)发现,使用100个Halton数估计参数的模拟方差低于1000个随机数。在125次霍尔顿抽取中,他们都发现模拟错误是1000次随机抽取的一半,比2000次随机抽取的小。估计过程要快得多(通常快10倍)。Hensher(2000)研究了涉及10、25、50、100、150和200次抽取的Halton序列(带有三个随机泛型参数),并在VTTS环境下与随机抽取进行了比较。在所有被研究的模型中,Hensher得出结论,少量的draw(低至25)产生的模型吻合度和平均VTTS几乎无法区分。这是复杂选择模型估计方面的一个显著发展。然而,在我们确定我们已经找到了最好的抽签策略之前,研究人员正在发现其他可能更好。例如,Sandor和Train(2002)对random、Halton、Niederreiter和正交数组抽取的研究发现,纯随机抽取的结果常常令人困惑,有时表现得比它们应该做的好得多,有时各种类型的抽取都比它们应该做的差得多。在估计的模拟方差中我们遗漏了什么?也许是由于优化算法不同的估计不同的绘图?最近Bhat对积分维数绘制类型的研究(已出版)表明,由于高维数序列的相关性,标准霍尔顿序列的均匀性在高维数中被打破。Bhat提出了一种打乱这些相关性的版本,以及一种计算方差估计的随机版本。这些最近研究的例子证明了对模拟绘图进行持续调查的必要性,特别是当强加分布的属性数量增加时。
 其次,方程(15)显示了偏好的异质性如何在不同的选择情况下导致相关的错误。这是通过两种选择情况下价格和其他属性之间的相互作用的参数化来揭示的。这种异质性是选择情况之间的一种特殊类型的相关性,人们还没有很好地理解。为了获得选择模型参数的有效估计,应该在模型中包含异质性结构的说明。Daniels和Hensher(2000)和Bhat和Castelar(2002)指出,如果没有明确地将偏好异质性考虑在内,那么可选误差之间的相关性可能会与未观察到的偏好异质性相混淆。其中一种方法是将与每个属性(包括price)关联的参数指定为随机,这正是混合logit模型的目的。只要认识到偏好异质性必须对所有备选方案在所有选择的情况下定义一个单独的年代选择反应(即数据集1、2和4中的16)然后通过显式相关性自动适应造型偏好异质性存在在所有选择的情况下所定义的基本随机参数的协方差矩阵。这种相关性对瞬时陈述的选择来说不太可能是自回归的,因为它不是长期积累经验的产物,通常归因于状态依赖。相反,它是在一个非常短的时间内,由同一个人评估的,在选择情况之间共享的偏好异质性的认知。这里的讨论假设每个用随机参数指定的属性在给定的选择情况下(在选项内和选项之间)独立于其他指定的属性。这个在下一节中讨论的限制可以放宽并进行测试。4.6 考虑参数之间的相关性 所有的数据集,不管每个抽样个体的选择情况的数量,都可能有未观察到的影响,这些影响与给定的选择情况下的备选方案相关。认识到这一点的一种方法是允许备选方案中常见的属性的随机参数之间的相关性。这产生了一个非对角估计的协方差矩阵,该矩阵识别可选方案内部和之间的属性之间的依赖关系(通过将每个随机参数的方差表示为一个误差成分)(取决于属性参数是否通用)。
其次,方程(15)显示了偏好的异质性如何在不同的选择情况下导致相关的错误。这是通过两种选择情况下价格和其他属性之间的相互作用的参数化来揭示的。这种异质性是选择情况之间的一种特殊类型的相关性,人们还没有很好地理解。为了获得选择模型参数的有效估计,应该在模型中包含异质性结构的说明。Daniels和Hensher(2000)和Bhat和Castelar(2002)指出,如果没有明确地将偏好异质性考虑在内,那么可选误差之间的相关性可能会与未观察到的偏好异质性相混淆。其中一种方法是将与每个属性(包括price)关联的参数指定为随机,这正是混合logit模型的目的。只要认识到偏好异质性必须对所有备选方案在所有选择的情况下定义一个单独的年代选择反应(即数据集1、2和4中的16)然后通过显式相关性自动适应造型偏好异质性存在在所有选择的情况下所定义的基本随机参数的协方差矩阵。这种相关性对瞬时陈述的选择来说不太可能是自回归的,因为它不是长期积累经验的产物,通常归因于状态依赖。相反,它是在一个非常短的时间内,由同一个人评估的,在选择情况之间共享的偏好异质性的认知。这里的讨论假设每个用随机参数指定的属性在给定的选择情况下(在选项内和选项之间)独立于其他指定的属性。这个在下一节中讨论的限制可以放宽并进行测试。4.6 考虑参数之间的相关性 所有的数据集,不管每个抽样个体的选择情况的数量,都可能有未观察到的影响,这些影响与给定的选择情况下的备选方案相关。认识到这一点的一种方法是允许备选方案中常见的属性的随机参数之间的相关性。这产生了一个非对角估计的协方差矩阵,该矩阵识别可选方案内部和之间的属性之间的依赖关系(通过将每个随机参数的方差表示为一个误差成分)(取决于属性参数是否通用)。


 为了研究约束对对数正态分布以外的分布的影响,我们估计了一个使用三角形分布的模型,对数据集3的扩展施加约束。将扩展设置为1.0可以保证一个非负号。任何其他值都将导致这两个符号。原因如下。和前面一样定义,βi scaleβit,在这里,t是范围从-1到 1的三角形分布。如果规模等于1.0,范围是0到2β1。我们发现,价差等于1.0的平均VTTS是$7.62(范围为$4.93到$14.1)。因此,与平均值为$2.51、范围从$5,848到$3,112的无界价差相比,整个分布在正的VTTS范围内(尽管99%的值在$200到$240的范围内)。下图显示了这两个分布。在此基础上,我们得出结论,一个下界三角形分布具有吸引力,因为它消除了对数正态的长尾,同时确保了WTP的行为正确的符号。对受限分布的初步调查表明了正在进行的研究的一个主要主题。
为了研究约束对对数正态分布以外的分布的影响,我们估计了一个使用三角形分布的模型,对数据集3的扩展施加约束。将扩展设置为1.0可以保证一个非负号。任何其他值都将导致这两个符号。原因如下。和前面一样定义,βi scaleβit,在这里,t是范围从-1到 1的三角形分布。如果规模等于1.0,范围是0到2β1。我们发现,价差等于1.0的平均VTTS是$7.62(范围为$4.93到$14.1)。因此,与平均值为$2.51、范围从$5,848到$3,112的无界价差相比,整个分布在正的VTTS范围内(尽管99%的值在$200到$240的范围内)。下图显示了这两个分布。在此基础上,我们得出结论,一个下界三角形分布具有吸引力,因为它消除了对数正态的长尾,同时确保了WTP的行为正确的符号。对受限分布的初步调查表明了正在进行的研究的一个主要主题。
2.5年,计量经济圈近1000篇不重类计量文章,
Econometrics Circle
数据系列:空间矩阵|工企数据|PM2.5|市场化指数|CO2数据|夜间灯光|官员方言|微观数据| 内部数据计量系列:匹配方法|内生性|工具变量|DID|面板数据|常用TOOL|中介调节|时间序列|RDD断点|合成控制|200篇合辑|因果识别|社会网络|空间DID数据处理:Stata|R|Python|缺失值|CHIP/ CHNS/CHARLS/CFPS/CGSS等|干货系列:能源环境|效率研究|空间计量|国际经贸|计量软件|商科研究|机器学习|SSCI|CSSCI|SSCI查询|名家经验计量经济圈组织了一个计量社群,有如下特征:热情互助最多、前沿趋势最多、社科资料最多、社科数据最多、科研牛人最多、海外名校最多。因此,建议积极进取和有强烈研习激情的中青年学者到社群交流探讨,始终坚信优秀是通过感染优秀而互相成就彼此的。