重磅干货,第一时间送达

使用OpenCV对0到9数字进行识别,实现简单OCR功能,基于CA(轮廓)分析实现特征提取,基于L1距离计算匹配实现数字识别。在排除干扰的基础上,识别精度可以达到98%以上。整个算法分为两个部分,第一部分是特征提取,提取的特征实现了尺度不变性与轻微光照与变形干扰排除,第二部分基于特征数据进行匹配实现了相似性比较,最终识别0到9十个数字。
第一部分详解:
算法的第一部分主要是实现以下功能,提取42个特征向量,用其中40个向量做匹配识别,另外两个向量做辅助检查。比如0跟1的横纵比有明显差别。特征提取的主要步骤如下:
1. 图像去噪声与二值化
2. 轮廓发现与ROI区域分割
3. 水平与垂直投影,提取20个向量,并归一化
4. 网格分割5×4,提取20个向量,并归一化
5. 宽高比与空白比,总计42个向量提取完成
预处理通过高斯模糊去噪声,然后通过全局阈值实现图像二值化,使用轮廓发现提取ROI矩形区域,对每个区域完成3~5步,实现特征提取,其中水平与垂直投影演示如下:
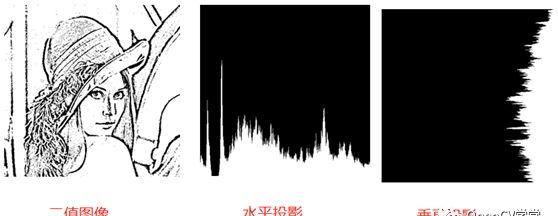
对ROI区域的水平与垂直投影分别分成10个BIN,考虑到浮点数划分,每个BIN长度不一定是整数,这样就通过权重进行按比例分割像素点。完成每个BIN的前景像素点统计。
同样对数字ROI区域实现5×4的网格分割,每个Cell计算前景像素个数,也会借助权重比例进行分割,最终得到归一化之后的20个特征向量。
这样得到的40个特征向量具有放缩不变性与轻微抗干扰变形能力。
第二部分详解:

运行截图:
训练数据:

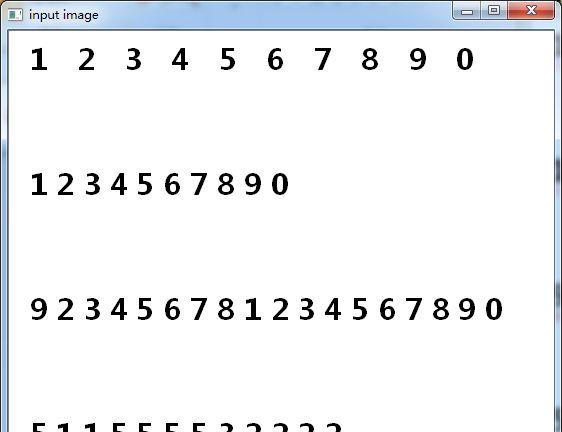
输入数据:
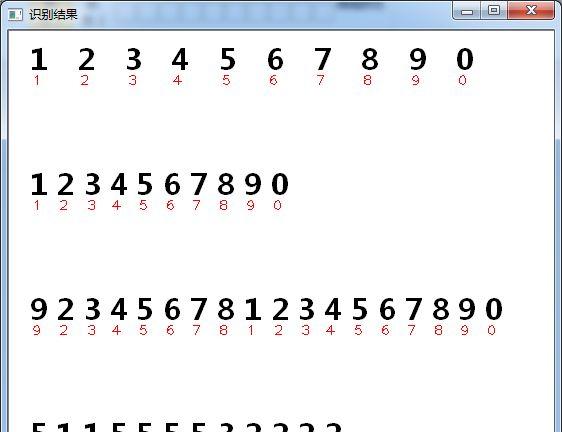
识别结果:
观察结论
训练数据和识别数据在字体、大小上均有差异,然而根据提取的特征进行匹配,均可识别,充分证明了本识别算法的尺度不变性与局部抗干扰能力。
执行代码
int main(int argc, char** argv) {
Mat src = imread(“D:/vcprojects/images/td1.png”);
if(src.empty()) {
printf(“could not load image…\n”);
return-1;
}
namedWindow(“input image”, CV_WINDOW_AUTOSIZE);
imshow(“input image”, src);
// 训练
train_data();
// 测试
test_data();
waitKey(0);
return0;
}
交流群